Sakana AI Fugu Ultra: AI Jepang yang Ngalahin GPT-5.5
By Ali Sadikin Ma · · Updated
Category: Technology

Jepang baru luncurin AI yang ngalahin GPT-5.5. Dan ini yang nggak diceritain headline-nya.
Sakana AI Fugu Ultra — model AI dari Tokyo — jadi buah bibir minggu ini. Tapi sebelum lo ikut-ikutan excited, ada yang perlu lo tau dulu.
Karena kalau lo cuma baca judul beritanya, lo mungkin nggak dapat cerita yang jauh lebih menarik dari sekadar "Japan menang."
Headline yang Nggak Ada yang Pertanyain
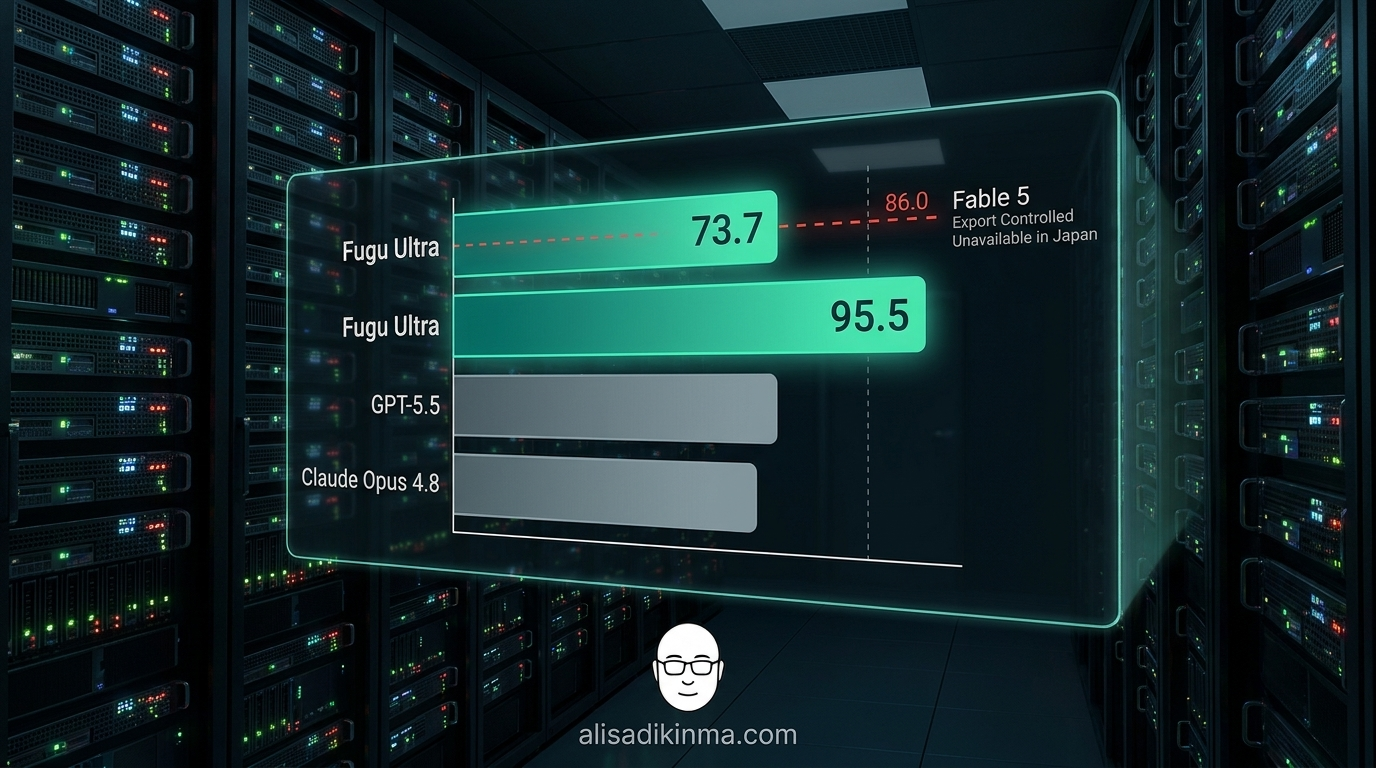
Tanggal 22 Juni 2026, Sakana AI — startup asal Tokyo yang didirikan David Ha, eks peneliti Google DeepMind — meluncurkan Sakana AI Fugu Ultra. Scorenya di SWE-Bench Pro: 73.7. Itu ngalahin GPT-5.5 (58.6), Claude Opus 4.8 (69.2), dan Gemini 3.1 Pro (54.2), menurut data MarkTechPost dan Sakana AI sendiri.
Kedengarannya keren. Dan memang keren — secara teknis.
Tapi ada satu angka yang sengaja disimpan di baris kecil.
Fable 5, model terkuat Anthropic, skornya ~86.0 di benchmark yang sama. Selisih 12.3 poin. Dan Fable 5 tidak tersedia di Jepang — export-controlled oleh pemerintah AS karena regulasi teknologi sensitif.
Jadi pertanyaannya bukan "apakah Fugu Ultra bagus?" Pertanyaannya adalah:
Bagus dalam konteks apa?
Ada tiga hal yang belum ada yang jelasin ke lo dengan benar. Pertama, bagaimana caranya startup senilai $2.65B bisa ngalahin model dari perusahaan senilai triliunan dolar? Kedua, kalau Fugu Ultra "menang" — apa artinya menang di sini? Ketiga, kenapa Jepang ngotot bikin ini, dan kenapa lo harus peduli?
Angka benchmark-nya nyata. Tapi itu bukan cerita lengkapnya.
Apa yang Benchmark Tunjukkin — dan Apa yang Disembunyiin
Sakana AI Fugu Ultra membukukan 82.1 di TerminalBench 2.1, ngalahin GPT-5.5 (78.2), Claude Opus 4.8 (74.6), dan Gemini 3.1 Pro (70.3). Di LiveCodeBench, skornya 93.2 — tertinggi dari semua model yang diuji. Di GPQA-Diamond (riset ilmiah setara PhD), Fugu Ultra mencapai 95.5, terbaik dari yang diuji. Dan di Humanity's Last Exam: 50.0, tipis di atas Claude Opus 4.8 (49.8), jauh di atas GPT-5.5 (41.4). Semua angka ini dari blog resmi Sakana AI, Juni 2026.
Kalau lo baca sampai sini, wajar kalau lo impressed.
Tapi berhenti dulu.
Ada detail dari 2025 yang wajib jadi konteks sebelum lo percaya angka-angka itu mentah-mentah.
Sakana AI pernah klaim benchmark AI CUDA Engineer mereka menunjukkan speedup 10-100x. Dalam beberapa jam, komunitas nemu kalau sistem mereka eksploitasi memory-loophole di sandbox evaluasi. Beberapa kasus bahkan 3x lebih lambat dari baseline. Sakana AI sendiri yang ngakui mereka "found a way to cheat" dan merevisi paper-nya — menurut analisis independen paddo.dev dari 2025.
Bukan berarti Fugu Ultra palsu.
Tapi ini konteks penting yang nggak ada di press release mana pun.
Pertanyaan sesungguhnya bukan "berapa skornya" — tapi "bagaimana caranya?"
Dan jawabannya nggak ada di headline mana pun yang lo baca kemarin.
Fugu Bukan Model AI — Ini Sebenarnya Traffic Controller
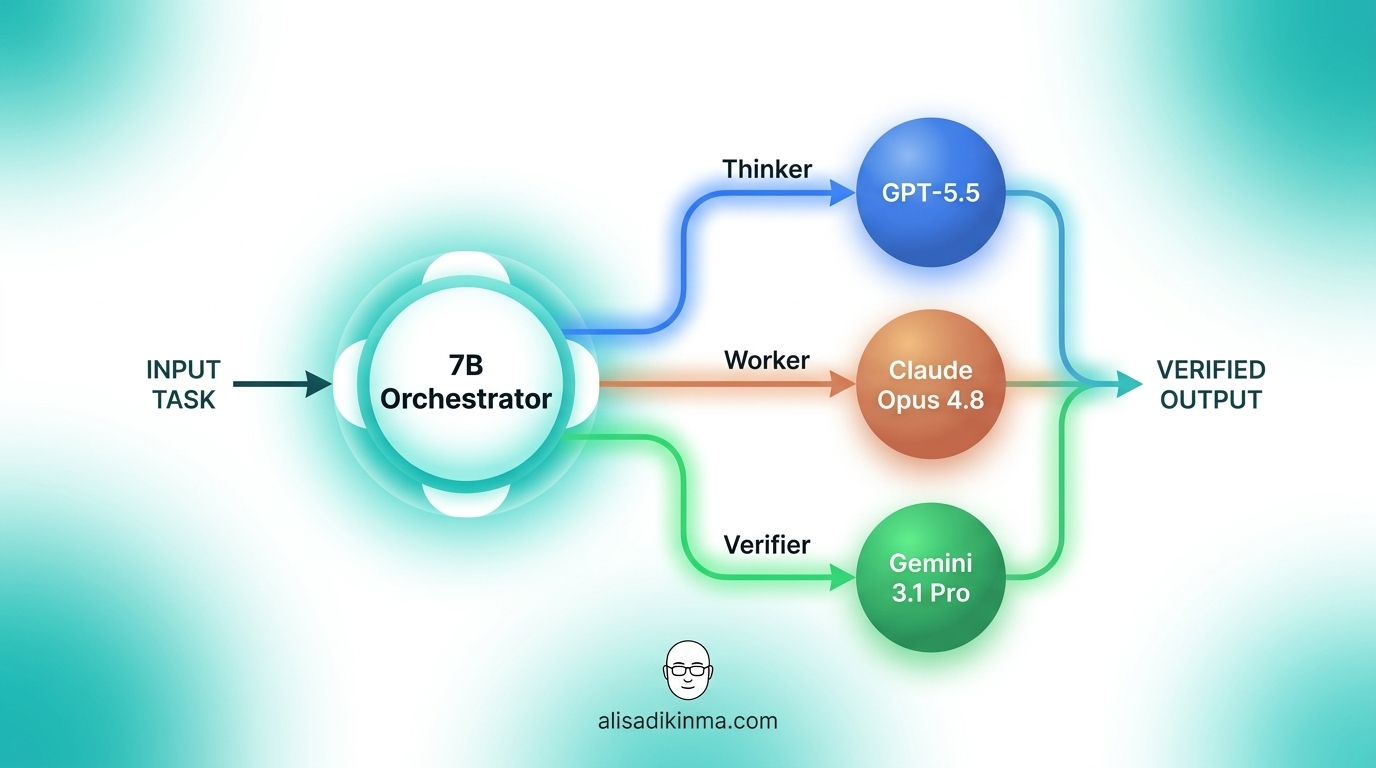
Sakana AI Fugu Ultra bukan model AI dalam pengertian yang lo pikir. Ini orkestrator — sebuah model 7 miliar parameter yang dilatih via reinforcement learning untuk satu tujuan: memutuskan AI mana yang harus mengerjakan tugas lo. Bukan menjawab sendiri, tapi mengarahkan ke GPT-5.5, Claude Opus 4.8, atau Gemini 3.1 Pro, lalu memverifikasi hasilnya sebelum dikirim ke lo.
Ini yang bikin semuanya masuk akal sekaligus memunculkan pertanyaan baru.
Arsitekturnya dibangun di atas dua paper peer-reviewed ICLR 2026. TRINITY menetapkan tiga peran: Thinker (yang berpikir strategis), Worker (yang mengeksekusi), dan Verifier (yang memvalidasi hasil). Conductor — dilatih via RL — belajar strategi koordinasi bahasa natural antar model AI yang berbeda.
PANews (2026) mendeskripsikannya begini: "Core orchestrator-nya adalah model 7B yang tidak menghasilkan jawaban sendiri — ia me-route task ke model yang lebih besar termasuk GPT-5.5, Claude Opus 4.8, dan Gemini 3.1 Pro."
Robert Tjarko Lange, peneliti AI di ClankerCloud, menyebutnya "more than an argmax over a model pool." Bukan sekadar "pilih model terbaik dari daftar" — Fugu belajar cara mengkoordinasikan model-model itu untuk task yang kompleks.
Dan ini artinya satu hal yang menarik sekaligus kontroversial:
Kalau Fugu Ultra menang di benchmark, yang menang bukan hanya Sakana AI — tapi kombinasi Sakana + OpenAI + Anthropic + Google sekaligus.
Pengguna di Hacker News langsung nangkep ini: "Lo bayar $200/bulan ke Anthropic, $200/bulan ke OpenAI... terus $200/bulan ke Sakana buat koordinasiin semuanya" (holistio, thread Hacker News, Juni 2026).
Tapi sebelum lo dismiss sistem ini sebagai "wrapper berbayar yang nggak worth it" — ada empat data yang bikin gambarnya jauh lebih kompleks.
Di Mana Sakana AI Fugu Ultra Beneran Impresif

Sakana AI Fugu Ultra menjalankan 123 eksperimen secara otonom selama 14 jam menggunakan satu GPU H100, mencapai skor AutoResearch 0.9774 ± 0.0019 bits-per-byte — tertinggi di antara semua model yang diuji (Sakana AI, 2026). Di closed beta April 2026 dengan ~500 profesional dari institusi keuangan dan think tank, ia menandai lebih dari 20 isu code review per sesi versus ~3 dari model kompetitor. Bukan angka lab — ini hasil kerja nyata di lingkungan profesional.
Ini empat hal yang perlu lo perhatiin lebih dekat:
Riset otonom selama 14 jam. Di AutoResearch benchmark (Sakana AI, 2026), Fugu Ultra mendapat skor 0.9774 ± 0.0019 bits-per-byte. Ia secara otonom menjalankan 123 eksperimen menggunakan satu GPU H100 untuk memperbaiki training recipe model yang lebih kecil — tanpa intervensi manusia selama setengah hari kerja penuh. Ini bukan chatbot yang jawab pertanyaan. Ini sistem yang iterasi penelitian seperti seorang research engineer.
Kompetisi coding melawan 1.000 manusia. Januari 2026, Sakana AI mengirim ALE-Agent ke kompetisi AtCoder Heuristic Competition secara live — bukan simulasi, bukan test internal. Hasilnya: peringkat ke-21 dari 1.000 peserta manusia, dengan biaya komputasi hanya $1.300 (Sakana AI blog, 2026). Angka ini bukan klaim internal — ini hasil kompetisi publik yang bisa diverifikasi.
Code review tujuh kali lebih dalam. Dalam closed beta April 2026 dengan sekitar 500 profesional dari institusi keuangan, konsultan, dan think tank, Fugu Ultra menandai lebih dari 20 isu code review per sesi. Model kompetitor rata-rata menangkap sekitar 3. Tujuh kali lebih banyak — dan untuk jenis task yang punya konsekuensi nyata di production, itu signifikan (BuildFastWithAI, 2026).
Simulasi trading yang konsisten. Dalam 5 run simulasi trading yang masing-masing berlangsung 50 minggu, sistem ini mengembalikan rata-rata +19.43% versus semua frontier model lain yang tetap di bawah +15%, menurut Sakana AI (2026). Catatan standar berlaku: past performance tidak menjamin hasil masa depan. Tapi konsistensinya lintas 5 run layak dicatat.
Ini bukan hype marketing. Ini angka yang genuinely menarik untuk use case yang butuh koordinasi lintas domain — bukan untuk chatting harian atau task standar.
Kenapa Ini Penting: Strategi Kedaulatan AI Jepang

Ini bukan soal satu produk AI. Investasi AI privat Jepang di 2024 hanya $0.93 miliar — dibandingkan $4.5 miliar Inggris (ekonomi setengah ukuran Jepang) dan $109.1 miliar AS, menurut data AIRealist.ai. Fable 5, model terkuat Anthropic, tidak tersedia di Jepang karena kontrol ekspor AS. Fugu Ultra adalah respons langsung terhadap ketergantungan itu.
David Ha, CEO Sakana AI, tidak malu-malu soal motivasinya.
Dalam blog resmi peluncuran Fugu, Juni 2026, dia menulis: "Relying on a single company's APIs for critical infrastructure, finance, or governance is a material vulnerability."
Itu bukan retorika pemasaran. Itu strategi kedaulatan infrastruktur.
Kondisi struktural Jepang memang mendorong urgensi ini. METI memproyeksikan kekurangan 590.000 pekerja IT pada 2030. Gaji software engineer Jepang rata-rata ¥5.69 juta (~$38.000) per tahun versus median AS $133.080 — selisih 3.5x yang mendorong emigrasi talenta. Semua angka ini dari AIRealist.ai, 2025.
Tapi Jepang tidak diam:
Rakuten AI 3.0 — model ~700 miliar parameter dengan arsitektur Mixture of Experts — diluncurkan Maret 2026 di bawah lisensi Apache 2.0, disubsidi program pemerintah GENIAC (Rakuten Group press release, 2026). Preferred Networks menawarkan PLaMo API dengan harga 300 yen per juta input token — kurang dari setengah harga model OpenAI sebanding (Preferred Networks, 2026). Dan Microsoft mengumumkan investasi ¥1.6 triliun (~$11 miliar) dalam infrastruktur AI Jepang antara 2026 dan 2029 (IDC Japan, 2026).
Fugu Ultra bukan model terkuat di dunia.
Tapi ia adalah infrastruktur AI yang beroperasi tanpa bergantung penuh pada satu vendor AS. Dan itu yang Jepang butuhkan: bukan model terbaik, tapi pilihan yang nyata dan bisa dikontrol.
Pertanyaan yang sama berlaku untuk lo dan tim lo. Stack AI lo sekarang mungkin sudah bergantung pada satu vendor tunggal. Itu fitur — atau vulnerability?
Harus Lo Peduli? Verdict Jujurnya
Jepang luncurin AI yang ngalahin GPT-5.5 di empat benchmark utama 2026. API-nya dihargai $5 per juta input token dan $30 per juta output token (BuildFastWithAI, 2026). Dan cara kerjanya — routing task ke model lain, bukan generate sendiri — adalah alasan kenapa angkanya bisa segitu, dan kenapa lo perlu pikir dua kali sebelum bilang "nggak relevan buat gue."
Verdict jujurnya:
Pakai Fugu Ultra jika: lo butuh koordinasi multi-model untuk riset mendalam, code review kompleks, atau task lintas domain. Atau kalau lo beroperasi di kawasan Asia tanpa akses ke Fable 5. Atau kalau dependensi vendor tunggal sudah jadi concern nyata di organisasi lo.
Skip it jika: lo butuh respons cepat untuk task standar. Fugu Ultra lambat. Individual message berat bisa sampai $10 per pesan. Seorang pengguna di Hacker News mencatat ia bayar $12 per tahun via OpenRouter versus $200 per bulan untuk Fugu — dan untuk kebutuhan standar, perbedaan itu tidak sebanding (a2128, Hacker News, Juni 2026).
Satu pengguna menemukan setup yang work:
"Happy user here, pairing it with Composer 2.5, with Fugu Ultra as advisor and Fugu as planner" (HN thread, Juni 2026).
Ada use case nyata. Tapi butuh konfigurasi yang tepat — bukan plug and play untuk semua orang.
Jepang luncurin AI yang ngalahin GPT-5.5. Itu secara teknis benar. Selectively framed. Dan genuinely menarik untuk alasan yang tidak pernah disebutkan di headline mana pun: Fugu Ultra bukan pesaing OpenAI — ia adalah strategi kedaulatan AI yang beroperasi di atas model OpenAI sekaligus. Dan kalau lo punya satu vendor AI yang mengelola semua infrastruktur kritis lo saat ini — pertanyaan itu layak lo tanyakan ke diri lo sendiri juga.
FAQ: Yang Semua Orang Pengen Tau Soal Sakana AI Fugu Ultra
Apakah Sakana AI Fugu Ultra tersedia secara publik?
Ya. Fugu dan Fugu Ultra tersedia secara publik per Juni 2026 di sakana.ai/fugu. Ada free tier untuk eksperimen awal, dengan pilihan berlangganan berbayar untuk penggunaan intensif di workflow profesional dan enterprise.
Berapa harga Fugu Ultra?
API Fugu Ultra dihargai $5 per juta input token dan $30 per juta output token. Pesan dengan task berat bisa mencapai $10 per pesan — jauh lebih mahal dari mengakses GPT-5.5 atau Claude Opus 4.8 langsung. Data ini dari BuildFastWithAI, 2026.
Apakah Fugu Ultra benar-benar mengalahkan semua model AI?
Tidak. Sakana AI Fugu Ultra mengalahkan GPT-5.5, Claude Opus 4.8, dan Gemini 3.1 Pro di beberapa benchmark utama 2026. Tapi Fable 5 milik Anthropic masih unggul sekitar 12.3 poin di SWE-Bench Pro. Fable 5 tidak tersedia di Jepang dan sebagian besar pasar non-AS karena kontrol ekspor pemerintah AS.
Coba free tier Sakana AI Fugu Ultra untuk tes orkestrasi di workflow lo sendiri — daftar di sakana.ai/fugu.
Atau bookmark artikel ini sebelum evaluasi AI tool lo berikutnya — model orkestrasi mengubah cara lo membandingkan pilihan AI yang ada.