Model AI Terkuat Bukan Selalu yang Bisa Kamu Pakai
By Ali Sadikin Ma · · Updated
Category: Technology

GPT-5.6 Sol diluncurkan 26 Juni 2026. Tapi kamu masih nggak bisa pakainya.
Aksesnya dibatasi hanya untuk organisasi mitra pemerintah yang sudah diverifikasi — tanpa waitlist publik, tanpa opsi daftar mandiri, tanpa tanggal pasti kapan tersedia untuk umum, menurut laporan TechTimes Juni 2026.
Dan kalau lo lagi memikirkan AI model selection untuk tim lo, ini bukan cuma soal model mana yang paling kuat. Ini soal model mana yang benar-benar bisa lo pakai — sekarang, di production, dengan budget yang ada.
Kenapa model AI terkuat selalu punya dinding yang susah dilewatin?
Tapi ada yang lebih bikin penasaran:
Di Q1 2026, 15 model frontier teratas semuanya skor di atas 96% di MATH-500. Selisihnya cuma 0.4 poin — dengan variasi antar-run 1.3 poin. Ranking benchmark di posisi teratas itu secara statistik nggak bisa dijadikan dasar keputusan pemilihan model, menurut LayerLens Q1 2026 Frontier Model Report.
Kalau performanya hampir identik, kenapa tim lo masih bayar premium price untuk frontier model?
Dan ada satu pertanyaan yang hampir nggak pernah dijawab:
Framework apa yang dipakai tim high-performing untuk AI model selection yang tepat — bukan yang paling kuat, tapi yang paling bisa dipakai dan menguntungkan secara bisnis?
Kenapa Semua Orang Masih Kejar Model AI yang Paling Kuat
Tim yang mengejar model AI terkuat biasanya berpegang pada asumsi yang salah: benchmark lebih tinggi berarti output lebih baik. Di Q1 2026, 15 model frontier teratas semuanya skor di atas 96% di MATH-500 dengan selisih hanya 0.4 poin — statistik yang nggak bermakna sebagai dasar pilihan, menurut LayerLens. Tapi closed model masih mendominasi 80% token usage dan 96% revenue di seluruh platform OpenRouter Mei–September 2025, menurut studi MIT Sloan.
Instinknya memang masuk akal.
Kalau benchmark-nya lebih tinggi, output-nya pasti lebih baik. Kalau modelnya terbaru, hasilnya pasti lebih akurat. Logika ini gampang diikuti — sampai lo lihat tagihannya.
Tapi inilah yang benchmark nggak pernah ceritain ke lo:
Open model sudah mencapai 89.6% performa closed model saat rilis — dan nutup sisa gap-nya dalam 13 minggu, turun dari 27 minggu setahun sebelumnya, menurut MIT Initiative on the Digital Economy 2025. Gap MMLU antara open dan closed model menyempit dari 17.5 poin persentase menjadi hanya 0.3 poin dalam satu tahun. Tapi kepercayaan pada nama brand tetap jauh lebih kuat dari kalkulasi ROI yang sebenarnya.
Dan ada empat hambatan konkret yang bikin masalah ini makin dalam.
4 Tembok yang Menghalangi Kamu dari Model Terbaik
Empat hambatan konkret mencegah tim dari menggunakan model AI yang tepat: biaya yang meledak di production, rate limits yang nggak terencana, keterbatasan privasi data, dan pembatasan akses model oleh safety frameworks. Forrester 2026 menemukan 70% CIO menyebut ketidakpastian biaya AI sebagai hambatan adopsi nomor satu — lebih tinggi dari kendala teknis maupun talent gaps.
Ini bukan soal skill tim lo yang kurang. Ini soal empat hambatan nyata yang hampir nggak pernah masuk dalam perencanaan anggaran AI.
1. Ledakan Biaya
Lo kira udah kalkulasi biaya AI dengan cermat. Lalu tagihan produksi datang.
Budget dev $40, tagihan produksi $680. Ini pola yang berulang di banyak tim — bukan kisah unik. Kenapa? Karena unit price per token memang turun, tapi token yang dikonsumsi per task naik lebih cepat dari penurunan harganya. Total tagihan bulanan tetap naik meski per-token cost terus turun, menurut Artefact 2026.
2. Rate Limits
Hambatan ini sering dilewatin saat planning — sampai sudah di production.
Menurut Retool State of AI Report 2025, 62% developer yang membangun aplikasi LLM API menyebut rate limiting sebagai tantangan operasional terbesar di production — di atas latency dan biaya. Nggak ada opsi dedicated capacity reservation di public API. Kalau traffic naik tiba-tiba, sistem lo antri duluan tanpa opsi prioritas.
3. Privasi Data
Data sensitif dan cloud-based frontier model nggak kompatibel secara fundamental.
Data kesehatan, keuangan, komunikasi internal — semuanya butuh jaminan data tetap di server lo sendiri. Closed model berarti data lo keluar dari infrastruktur lo. Nggak ada middle ground untuk use case seperti ini.
4. Pembatasan Akses
Dan ada satu hambatan yang hampir nggak pernah tim rencanakan:
Model frontier terkuat seringkali belum bisa diakses publik. GPT-5.6 Sol bukan yang pertama dan bukan yang terakhir. Lebih dari 12 perusahaan AI sudah menerbitkan Frontier AI Safety Frameworks dengan capability thresholds yang bisa memicu pembatasan akses sewaktu-waktu, menurut METR Common Elements of Frontier AI Safety Policies 2025. Model yang lo rencanakan untuk dipakai bulan depan bisa tiba-tiba nggak tersedia.
5 Pertanyaan yang Dipakai Tim Terbaik untuk AI Model Selection

Lima pertanyaan ini adalah framework AI model selection yang dipakai tim high-performing untuk routing cerdas — menghemat biaya tanpa mengorbankan kualitas output. AlterSquare 2025 menemukan 85% LLM API request bisa dirouting ke model cepat dan murah. Hanya 15% yang benar-benar butuh kemampuan frontier-scale.
Tim lo mungkin bayar frontier prices untuk 85% pekerjaan yang nggak butuh frontier capability.
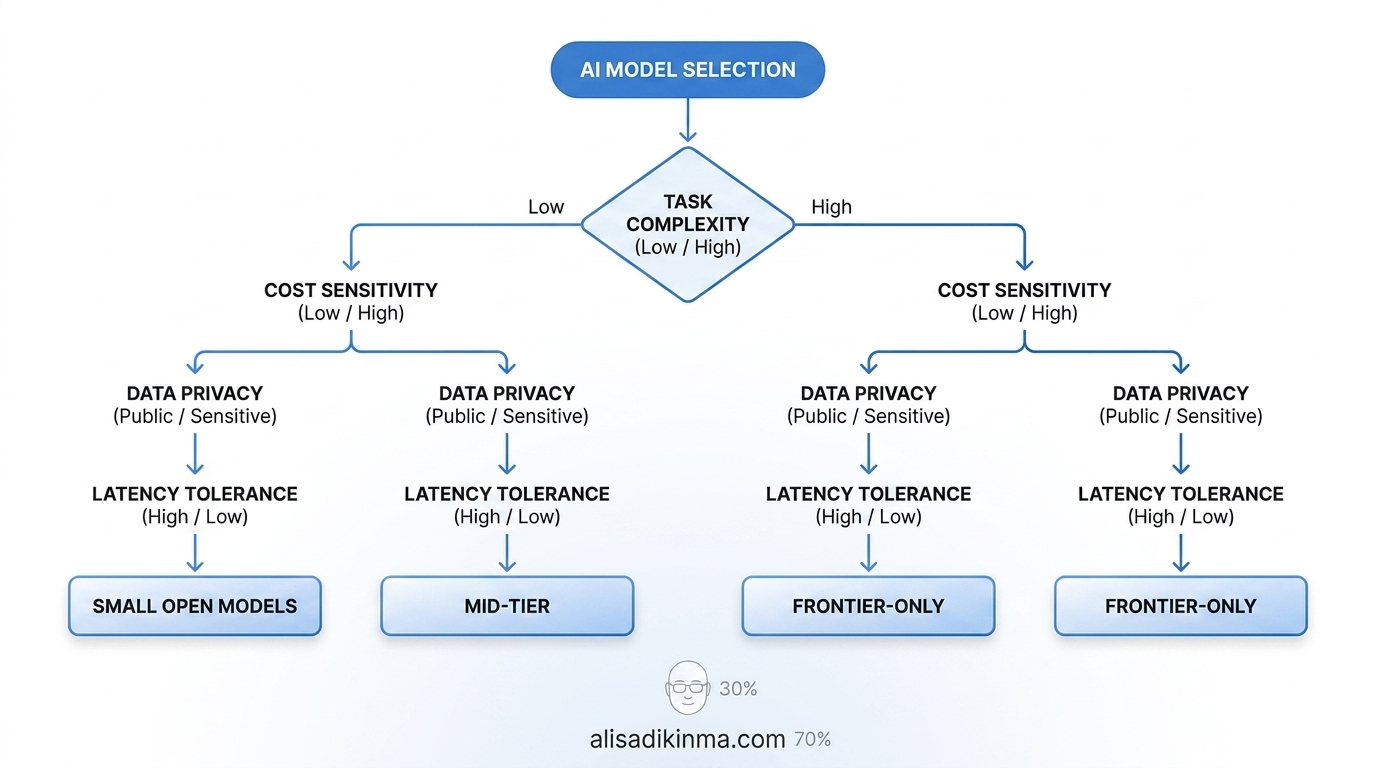
1. Seberapa Kompleks Task Ini?
Apa yang perlu lo lakukan: Klasifikasikan task berdasarkan level reasoning yang dibutuhkan — bukan berdasarkan kebiasaan atau asumsi bahwa model lebih kuat selalu menghasilkan output lebih baik untuk semua jenis pekerjaan.
Cara melakukannya: Pisahkan semua task AI tim lo menjadi tiga kategori. Kategori A adalah output formulaik dan repetitif — summarization pendek, formatting, classification, dan tagging. Kategori B mencakup reasoning multi-langkah, draft konten kompleks, dan analisis data terstruktur. Kategori C adalah task yang butuh nuance tinggi, creative problem-solving mendalam, atau domain expertise yang sangat spesifik. Mapping ini bisa dilakukan dengan spreadsheet sederhana: kolom task, kolom kategori, kolom model yang dipakai sekarang, kolom biaya aktual per bulan.
Contoh nyata: Tim engineering yang paham unit economics AI menggunakan Groq dan Ollama untuk Kategori A, DeepSeek dan Mistral untuk Kategori B, dan hanya menyentuh Anthropic Claude atau OpenAI untuk Kategori C yang kritikal. Distribusi biayanya proporsional dengan nilai yang dihasilkan — bukan rata di semua workload.
Outcome: Routing yang tepat berdasarkan kompleksitas task bisa memangkas 50–70% token spend tanpa menurunkan kualitas output yang dirasakan end user.
2. Berapa Biaya per Output yang Masuk Akal?
Apa yang perlu lo lakukan: Hitung unit economics per output — bukan total budget. Berapa biaya untuk menghasilkan satu unit kerja yang tim lo butuhkan? Angka ini yang jadi dasar keputusan, bukan feeling soal kualitas.
Cara melakukannya: Kalikan rata-rata token per request dengan harga per million tokens model yang lo pakai, lalu bandingkan antar pilihan. Mulai dari referensi ini: GPT-4-level performance sekarang tersedia di bawah $1 per million tokens — turun dari $30 di 2023, penurunan 97% dalam tiga tahun, menurut LLM Stats AI Trends Juni 2026. Lalu bandingkan dengan open alternatives. MIT Sloan menemukan closed model rata-rata 87% lebih mahal ($1.86 vs $0.23 per million tokens) dibanding open model yang comparable untuk lima bulan berturut-turut.
Contoh nyata: Untuk summarization artikel dengan rata-rata 500 token per request, frontier model menghabiskan sekitar $0.93 per 1.000 artikel. Model mid-tier open-source menghasilkan output yang comparable dengan $0.12 per 1.000 artikel. Untuk volume 10.000 artikel per bulan, selisihnya lebih dari $8.100 per bulan dari satu workload saja.
Outcome: Clarity yang jelas soal mana yang worth bayar premium — dan mana yang buang budget tanpa return yang bisa diukur.
3. Apakah Data Ini Boleh Keluar dari Server Lo?
Apa yang perlu lo lakukan: Ini pertanyaan binary. Data sensitif nggak bisa diproses via cloud-based model — titik. Ini bukan pilihan teknologi, ini kewajiban compliance yang nggak bisa dikompromikan dengan alasan apapun.
Cara melakukannya: Definisikan data classification level sebelum pilih model. Buat tiga kelas: Public (aman diproses via API manapun), Internal (perlu enkripsi dan audit trail), Confidential (wajib self-hosted). Untuk kelas Confidential, pakai open model yang di-deploy di infrastruktur lo sendiri. Ollama dan LM Studio memungkinkan running model secara lokal dengan setup minimal. Open model sekarang mencapai 89.6% performa closed model saat rilis dan nutup gap-nya dalam 13 minggu, menurut MIT Initiative on the Digital Economy 2025.
Contoh nyata: Perusahaan di industri kesehatan yang butuh AI untuk analisis data pasien tidak punya pilihan selain self-hosted open model. Dengan LM Studio, mereka mendapatkan performa yang cukup sambil menjaga compliance penuh — dan menghemat 87% dibanding closed alternatives yang nggak bisa dipakai untuk use case ini.
Outcome: Compliance terjaga dan biaya turun sekaligus. Untuk data sensitif, open model bukan cuma pilihan yang lebih murah — tapi satu-satunya pilihan yang legal.
4. Berapa Latency yang Bisa Ditoleransi?
Apa yang perlu lo lakukan: Bedakan antara task yang butuh real-time response dan yang bisa berjalan async. Ini menentukan arsitektur — dan pilihan model yang sesuai.
Cara melakukannya: Frontier model via public API punya P50 time-to-first-token 200–600ms — belum termasuk delay antrian akibat rate limits saat traffic tinggi, menurut Spheron Blog 2026. Identifikasi setiap task: apakah user menunggu response secara real-time, atau hasilnya bisa dikirim setelah proses selesai? Task yang bisa dibatch secara async bisa pakai model murah dengan throughput tinggi. Task yang butuh response instan butuh model ringan yang di-deploy sendiri atau Groq LPU yang didesain khusus untuk inference cepat dengan latency minimal.
Contoh nyata: Chatbot customer service butuh real-time response — kandidat untuk model yang di-deploy di infrastruktur sendiri dengan Groq atau Ollama. Email classification, content tagging, dan daily report generation bisa berjalan secara batch async di luar jam peak, dengan biaya 10x lebih murah dibanding memproses real-time di frontier model.
Outcome: User experience yang lebih responsif untuk task yang benar-benar butuh kecepatan, dengan cost yang jauh lebih rendah untuk mayoritas workload yang bisa berjalan async.
5. Apakah Open Model Sudah Cukup untuk Task Ini?
Apa yang perlu lo lakukan: Jangan asumsikan butuh frontier model sampai lo sudah test open alternatives. Gap kapabilitas menyempit dengan sangat cepat — lebih cepat dari yang kebanyakan tim sadari saat ini.
Cara melakukannya: Test open model dulu sebelum commit ke closed model. Pakai Hugging Face — lebih dari 2 juta model tersedia untuk dicoba tanpa biaya. Data terbaru: model 3B–14B parameter hari ini setara dengan model 70B dari 12–18 bulan lalu pada targeted production tasks, menurut Seldo.com 2026. DeepSeek menawarkan performa benchmark setara Claude dengan biaya 28x lebih murah. Alibaba Qwen sudah diunduh lebih dari 1 miliar kali dan menguasai lebih dari 50% semua open model downloads global per Januari 2026 — ini bukan niche market lagi.
Contoh nyata: Developer yang beralih dari frontier ke Qwen untuk text generation melaporkan kualitas output yang comparable dengan penghematan 60–80% monthly spend. Untuk kebanyakan content task, perbedaan output antara open mid-tier dan frontier nggak bisa dibedakan oleh end user.
Outcome: Kapabilitas yang lebih dari cukup untuk sebagian besar task, dengan fraction of the cost — dan kontrol penuh atas infrastruktur lo sendiri.
Seperti Apa 3-Tier Model Stack dalam Praktik
Stack AI 3-tier membagi model berdasarkan kebutuhan nyata: model ringan untuk task volume tinggi, model mid-tier untuk reasoning kompleks, dan frontier model hanya untuk yang benar-benar kritikal. LLM Stats AI Trends Juni 2026 mencatat GPT-4-level performance sekarang tersedia di bawah $1 per million tokens — turun 97% dari $30 di 2023. Tapi pilihan model yang tepat bukan soal harga saja, tapi soal matching kapabilitas dengan kebutuhan task yang sesungguhnya.
Begini arsitektur yang dipakai tim engineering yang serius soal unit economics AI:
Tier 1 — Volume Tinggi, Kecepatan Tinggi: Ollama, Groq, LM Studio. Untuk task repetitif — classification, formatting, summarization pendek, tagging. Biaya paling rendah, latency paling rendah, cocok untuk 85% workload yang ada.
Tier 2 — Reasoning Kompleks: Mistral AI, Together AI, DeepSeek. Untuk draft konten kompleks, analisis multi-langkah, dan task yang butuh nuance. Mid-cost dengan kapabilitas solid untuk sebagian besar kebutuhan production yang demanding.
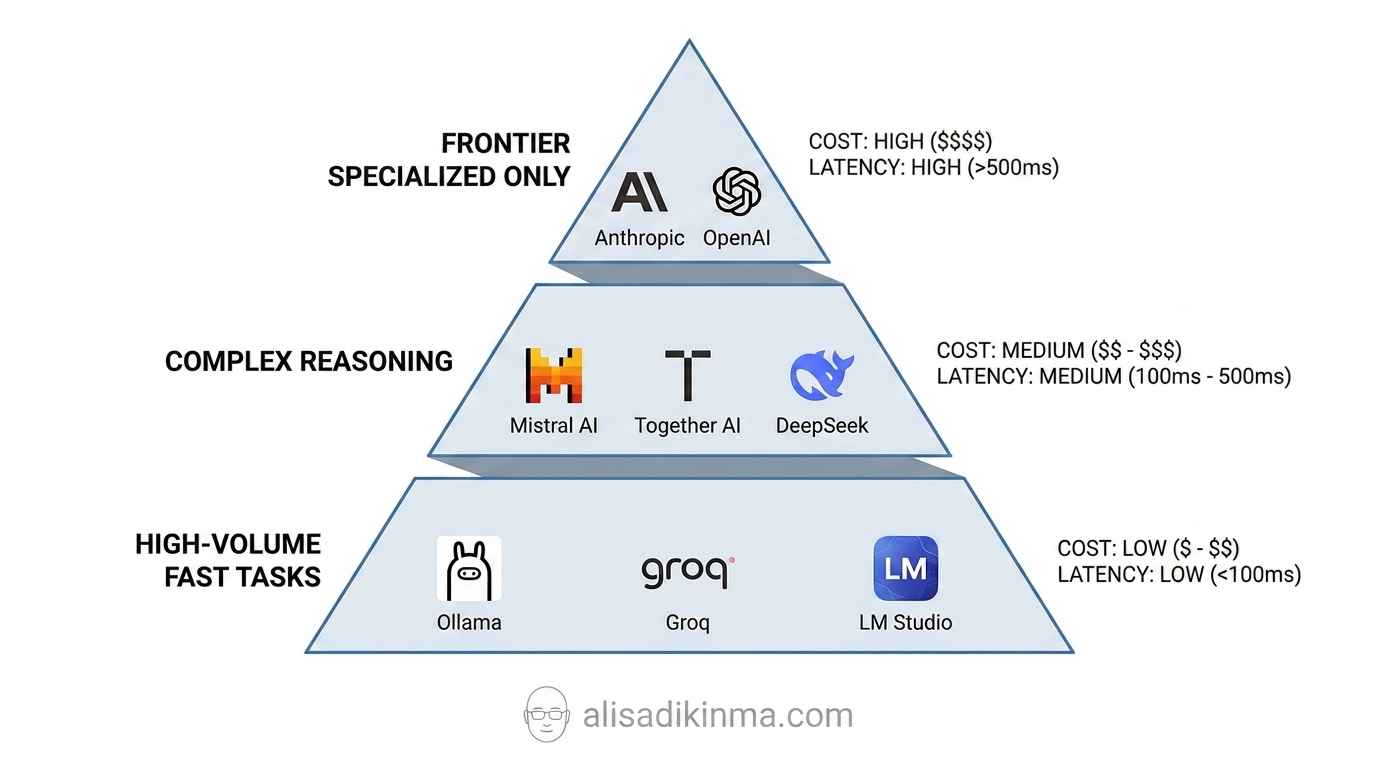
Tier 3 — Frontier, Dipakai dengan Cermat: Anthropic Claude, OpenAI. Hanya untuk task yang benar-benar butuh state-of-the-art — creative problem-solving tingkat tinggi, domain expert reasoning, atau output yang langsung dihadapkan ke klien premium.
Dan ini bukan sekadar teori.
Menurut AlterSquare AI Engineering Analysis 2025, untuk setiap $1 yang dihabiskan membangun model AI, $5–$10 harus dihabiskan untuk membuatnya siap production — monitoring, integrasi, scaling, dan reliability infrastructure. Pilihan model yang salah bukan cuma mahal saat runtime, tapi mahal di seluruh lifecycle production-nya.
Tim yang membangun stack 3-tier seperti ini mempertahankan output quality sambil memangkas AI spend secara signifikan — dan punya stack yang jauh lebih tahan terhadap perubahan harga atau kebijakan akses dari satu provider manapun.
Pergeseran yang Mengubah Cara Lo Ship AI
Pergeseran paling berdampak dalam AI development bukan soal model terkuat — tapi AI model selection yang cerdas berdasarkan task nyata dan unit economics yang masuk akal. MIT Initiative on the Digital Economy 2025 menghitung bahwa realokasi optimal workload enterprise AI dari closed ke open model bisa menghemat $25 miliar per tahun di seluruh ekonomi AI global. Selisih 3.3% performa antara model closed dan open terbaik di LMSYS Arena — itulah yang lo bayar 87% lebih mahal untuk mendapatkannya, menurut Stanford HAI 2026 AI Index Report.
Ingat GPT-5.6 Sol dari awal artikel ini?
Model AI paling kuat yang ada saat ini — dan lo masih nggak bisa pakainya. Bukan karena tim lo kurang mampu. Tapi karena inilah kenyataan struktural yang akan terus berulang di setiap generasi model frontier berikutnya.
Di sinilah insight yang sebenarnya:
Breakthrough AI berikutnya bukan soal model yang paling kuat. Ini soal model yang paling bisa lo ship — dengan stack yang dirancang untuk task nyata, unit economics yang masuk akal, dan kontrol infrastruktur yang nggak bergantung pada keputusan akses dari satu provider.
Satu workload apa di tim lo minggu ini yang lo routing ke frontier model, padahal model yang lebih kecil sudah lebih dari cukup?
FAQ — Pertanyaan Umum soal AI Model Selection
Apakah open-source AI model sudah cukup baik untuk production?
Ya, untuk sebagian besar task production. Open-source AI models sekarang mencapai 89.6% performa closed model saat rilis dan nutup sisa gap dalam 13 minggu — turun dari 27 minggu setahun sebelumnya, menurut MIT Initiative on the Digital Economy 2025. Selisih performa antara model open dan closed terbaik di LMSYS Arena hanya 3.3% per Stanford HAI 2026 AI Index. Untuk task yang butuh privasi data atau volume tinggi, open model bukan cuma alternatif yang lebih murah — tapi pilihan yang lebih cerdas secara keseluruhan.
Kenapa benchmark AI tidak cukup untuk memilih model yang tepat?
Karena benchmark mengukur kondisi lab yang terkontrol, bukan kondisi production nyata. Di Q1 2026, 15 model frontier teratas semuanya skor di atas 96% pada MATH-500 dengan selisih hanya 0.4 poin — tidak signifikan secara statistik menurut LayerLens. Enterprise agentic AI systems menunjukkan gap 37% antara skor benchmark lab dan performa deployment nyata, dengan variasi biaya 50x untuk tingkat akurasi yang serupa, menurut Kili Technology AI Benchmarks Guide 2026.
Mulai routing lebih cerdas sekarang — pakai 5 pertanyaan di atas untuk audit satu AI workload di tim lo minggu ini. Butuh kurang dari 30 menit, dan hasilnya akan mengubah cara lo melihat pengeluaran AI tim lo.
Belum siap restrukturisasi stack? Simpan artikel ini untuk review arsitektur berikutnya. Kalkulasi biayanya akan mengubah cara lo melihat ranking model AI selamanya.