GPT-5.5: OpenAI Bukan Update — Mereka Build Ulang dari Nol
By Ali Sadikin Ma · · Updated
Category: Technology

GPT-5.5 bukan versi baru. Ini model yang dibangun dari nol.
Tanggal 23 April 2026, OpenAI rilis GPT-5.5. Dalam 24 jam pertama, model ini langsung puncaki Artificial Analysis Intelligence Index dengan skor 60 — mengalahkan semua yang pernah ada sebelumnya.
Tapi bukan itu yang bikin berbeda.
Yang bikin berbeda adalah kenapa ini terjadi.
Setiap model GPT-5 sebelumnya — dari 5.0 sampai 5.4 — dibangun di atas fondasi yang sama. Post-training iteration. Fine-tuning. Alignment. Tapi fondasinya identik sejak GPT-4.5. Setiap "upgrade" yang keluar selama dua tahun terakhir pada dasarnya adalah model yang sama dengan tambalan baru di atasnya.
GPT-5.5? OpenAI buang semua itu.
Mulai dari scratch. Architecture baru. Training data baru. Foundation baru. Ini pertama kalinya sejak GPT-4.5 mereka benar-benar retrain base model dari awal — dan hasilnya bikin kompetitor pusing kepala.
Tapi ada satu pertanyaan yang belum terjawab:
Apakah rebuild dari nol ini benar-benar terasa di dunia nyata, atau hanya angka di benchmark yang tidak relevan buat mayoritas user?
Dan ada satu hal yang bahkan lebih mengejutkan dari semua benchmark itu:
GPT-5.5 baru saja bantu ilmuwan buktikan teorema matematika yang sudah dikejar manusia selama lebih dari 90 tahun.
Itu bukan klaim marketing. Itu research announcement resmi dari OpenAI sendiri.
Kita bongkar satu per satu.
1. OpenAI Buang Fondasi Lama — GPT-5.5 Dimulai dari Nol
GPT-5.5 adalah base model pertama yang di-retrain sepenuhnya sejak GPT-4.5 — artinya setiap model dari GPT-5.0 sampai 5.4 adalah variasi post-training dari fondasi yang sama. GPT-5.5 punya architecture yang benar-benar baru, dan hasilnya terlihat langsung: BenchLM kasih skor 93/100 di evaluasi provisional pertama, ranked #2 dari 115 model yang mereka track.
Bukan #2 di antara model baru 2026. #2 dari semua model yang pernah ada.
Kenapa ini penting?
Analoginya begini: post-training bisa bikin model lebih pintar, tapi ada batas. Kamu bisa fine-tune seekor ikan sampai dia bisa navigasi air lebih efisien — tapi dia tetap ikan. Retrain base model artinya kamu ganti DNA-nya dari awal.
Setiap GPT-5 dari versi 5.0 sampai 5.4 adalah versi ikan yang makin pintar berenang. GPT-5.5 adalah spesies yang berbeda.
Ini konfirmasi resmi dari OpenAI: model ini bukan iterasi dari GPT-5 series yang sudah ada — ini fondasi baru yang akan jadi basis generasi berikutnya.
Pertanyaannya: di area mana perbedaannya paling drastis untuk pekerjaan sehari-hari?
2. GPT-5.5 Nulis Kode Kayak Senior Engineer, Bukan Chatbot
GPT-5.5 mencapai 82.7% di Terminal-Bench 2.0 — benchmark yang mengukur agentic coding di environment terminal nyata, bukan sandbox simulasi. Claude Opus 4.7, model terbaik Anthropic yang ada saat ini, dapat 69.4% di tes yang sama. Selisihnya 13 poin lebih. Dalam dunia AI benchmarks, itu bukan tipis.
Tapi apa yang sebenarnya diukur Terminal-Bench 2.0?
Bukan syntax completion. Bukan autocomplete sederhana. Model harus:
- Baca dan interpretasi error log dari terminal nyata
- Debug proyek multi-file tanpa guidance dari manusia
- Tulis kode yang langsung bisa jalan — bukan kode yang perlu diedit ulang dua kali
GPT-5.5 tidak hanya suggest kode. Dia execute end-to-end.
Cara pakai praktisnya sekarang:
Connect GPT-5.5 via API ke IDE kamu — Cursor, VS Code dengan OpenAI extension, atau GitHub Copilot yang sudah support custom API endpoint. Assign task yang lengkap, bukan sub-task kecil. Contoh konkret: "Refactor module authentication ini untuk support OAuth 2.0 dan tambah unit test" — bukan "Tulis function untuk refresh token."
Hasilnya, berdasarkan benchmark independen CodeRabbit 2026: GPT-5.5 outperform semua model sebelumnya di realistic debugging tasks. Developer yang pakai agentic coding workflow bisa ekspektasi penghematan waktu nyata di debugging dan refactoring cycles — terutama untuk bug yang butuh baca banyak file sekaligus.
Tapi kemampuan coding itu baru bagian pertama. Ada satu upgrade yang lebih penting untuk semua use case yang butuh context panjang...
3. Memory 1 Juta Token — dan Kali Ini Benar-Benar Jalan
GPT-5.5 mencapai 74.0% pada MRCR v2 benchmark di context window 1 juta token. GPT-5.4 dapat 36.6% di tes yang sama. Dari 36.6% ke 74.0% — lebih dari dua kali lipat dalam satu generasi model, menurut data resmi OpenAI 2026.
MRCR v2 bukan tes sederhana.
Benchmark ini tidak ukur apakah model "bisa" menerima 1 juta token. Dia ukur apakah model bisa recall dan gunakan informasi dari token ke-50,000 saat sedang memproses token ke-900,000.
Perbedaannya krusial:
GPT-5.4 bisa terima 1M token. GPT-5.5 benar-benar menggunakan 1M token.
Ini penting untuk:
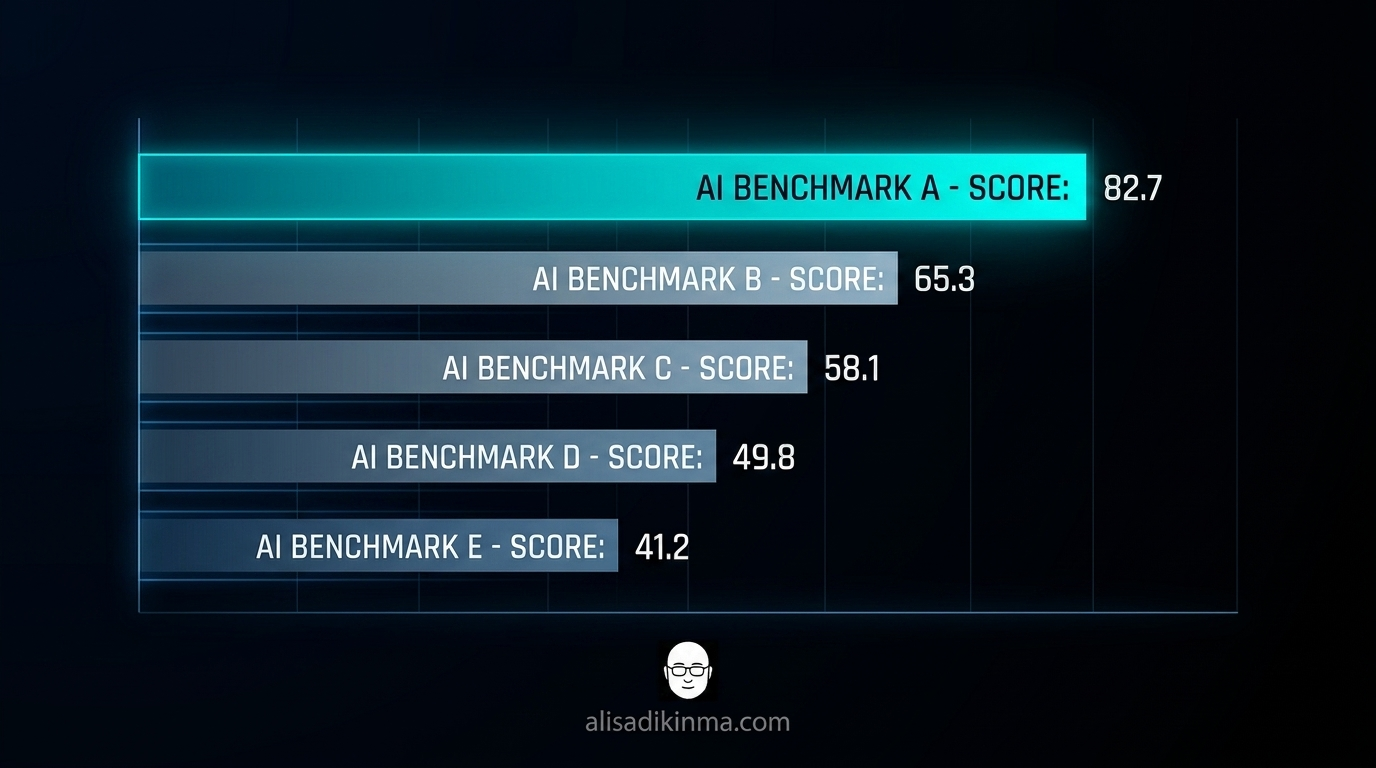
- Codebase review — model bisa maintain context dari seluruh repo, bukan hanya file yang sedang aktif dibuka
- Multi-session agents — agent bisa hold state sepanjang proyek panjang tanpa kehilangan context di tengah jalan
- Document analysis — kontrak panjang, research paper, atau legal brief bisa dianalisis end-to-end tanpa model "lupa" apa yang dibaca di awal
Kalau kamu pernah frustrasi karena AI agent seperti amnesia setelah conversation panjang — ini yang fix itu.
4. Satu Benchmark yang Bikin Developer Tercengang
GPT-5.5 mencapai 58.6% pada SWE-Bench Pro — benchmark yang mengukur kemampuan model menyelesaikan real-world GitHub issues dalam satu pass, tanpa human input. Lebih dari separuh bug reports nyata dari open-source repos bisa di-resolve GPT-5.5 secara mandiri, menurut data OpenAI dan CodeRabbit 2026.
Ini bukan tes nulis kode baru.
SWE-Bench Pro ambil bug reports asli dari repos aktif, kasih ke model, dan evaluasi apakah fix-nya benar-benar menyelesaikan masalah — bukan hanya compiles, tapi benar-benar passed regression tests.
Cara integrasikan ke workflow kamu:
Buat automation script sederhana yang pass issue title, description, dan relevant file contents ke GPT-5.5 via API. Minta model output tiga hal: (1) root cause analysis dalam 3 kalimat, (2) proposed fix dengan diff yang siap di-apply, (3) test case yang perlu diupdate atau ditambah.
Tim kecil atau solo developer bisa assign GPT-5.5 ke bug triage pipeline. Model handle 58%+ issues secara mandiri — kamu focus ke review dan high-complexity cases yang butuh human judgment dan domain knowledge spesifik.
Hasilnya nyata: untuk sprint 2 minggu dengan 30 open issues, estimasi konservatif adalah penghematan 40-60% waktu debugging berdasarkan benchmark CodeRabbit 2026. Itu belasan jam per sprint yang bisa dialihkan ke feature development.
Dan ini masih di domain "expected" — coding dan debugging. Ada satu domain yang tidak ada yang expect GPT-5.5 bisa masuk sejauh ini...
5. Ilmuwan Sekarang Punya Partner Riset yang Tidak Pernah Tidur
GPT-5.5 berkontribusi pada penemuan jalur bukti baru untuk masalah Ramsey numbers — problem kombinatorik yang sudah dikejar matematikawan selama lebih dari 90 tahun. Mark Chen, Chief Research Officer OpenAI, menyatakan ke TechCrunch pada April 2026 bahwa GPT-5.5 "shows meaningful gains on scientific and technical research workflows" dan berpotensi bantu di area drug discovery.
Ramsey numbers bukan problem sembarangan.
Problem ini sudah ada sejak 1930. Pertanyaannya terdengar sederhana: seberapa besar sebuah struktur matematika harus dibuat sebelum keteraturan tertentu pasti muncul di dalamnya? Tapi jawaban formalnya sudah dikejar selama hampir satu abad — oleh beberapa matematikawan terbaik yang pernah hidup.
GPT-5.5 tidak solve problem ini sendirian.
Tapi dia jadi kolaborator yang bisa explore search space di kecepatan yang tidak mungkin dilakukan manusia — membantu tim riset OpenAI menemukan jalur bukti baru yang belum pernah ditemukan sebelumnya.
Mark Chen menyebut drug discovery sebagai area berikutnya yang bisa tersentuh kemampuan ini. Kalau reasoning ilmiah GPT-5.5 diterapkan ke compound screening atau protein folding analysis, implikasinya jauh melampaui dunia AI produktivitas.
Ini yang menutup loop yang kita buka di awal: GPT-5.5 bukan hanya alat produktivitas yang lebih cepat. Ini kolaborator riset yang bisa jadi bagian dari penemuan ilmiah nyata.

6. Kompetisi Enterprise AI Baru Saja Naik Level
68% organisasi saat ini berada di tahap adopsi GenAI yang advanced, dan OpenAI memimpin dengan 57% market share di model adoption, menurut Futurum Group 2026. GPT-5.5 hadir tepat di saat persaingan enterprise AI paling ketat dalam sejarah adopsinya — dan langsung mengubah baseline evaluasi.
Artinya apa untuk tim yang evaluasi stack sekarang?
Vendor yang masih tawarkan GPT-5.4 atau model sebelumnya punya PR yang makin berat. Selisih 13 poin di agentic coding benchmark bukan angka yang mudah di-dismiss dalam procurement cycle — apalagi kalau tim engineering sudah lihat sendiri hasilnya di pilot.
Untuk tim engineering yang evaluate AI stack baru:
GPT-5.5 mengubah baseline. Use case yang sebelumnya "good enough" dengan GPT-5.4 mungkin tidak lagi kompetitif — terutama untuk agentic workflows, long-context processing, atau scientific reasoning intensif.
Tapi sebelum kamu restart semua evaluasi dari nol, ada satu pertanyaan praktis yang paling sering ditanya:
Kalau modelnya jauh lebih cerdas, pasti tokennya jauh lebih mahal?
7. Lebih Cerdas, Token Sama — Ini yang Perlu Kamu Tahu
GPT-5.5 mempertahankan efisiensi token yang setara dengan GPT-5.4 di tingkat kecerdasan yang lebih tinggi. Berdasarkan data LLM-Stats 2026, pricing API GPT-5.5 berada di level yang sama dengan GPT-5.4, sementara output quality per call meningkat secara nyata di semua kategori benchmark utama.
Ini jarang terjadi di siklus model AI.
Biasanya: intelligence upgrade = cost spike per token. OpenAI breaking that pattern di GPT-5.5.
Kenapa bisa lebih hemat total?
Karena model yang lebih cerdas butuh lebih sedikit back-and-forth untuk sampai ke jawaban yang benar. Re-prompting berkurang. Error correction berkurang. Total token consumed per task bisa lebih rendah — meski kamu bayar rate yang sama per token.
Untuk tim yang optimize AI spend: ini bukan sekadar "model lebih bagus dengan harga sama." Ini potentially ROI yang lebih tinggi per dollar API — terutama untuk workflows yang selama ini butuh banyak iterasi untuk sampai ke output yang bisa dipakai.
Bonus: Problem Matematika yang Dikejar Dekade — Akhirnya Ada Titik Terang
Ramsey numbers problem sudah ada sejak 1930. Selama 96 tahun, matematikawan terbaik dunia — di universitas paling bergengsi, dengan resources terbaik yang tersedia — belum bisa sepenuhnya solve problem ini.
GPT-5.5, sebagai kolaborator riset aktif, berhasil contribute pada penemuan jalur bukti baru yang belum pernah ditemukan manusia sebelumnya.
Ini menutup loop yang kita buka di pembukaan artikel ini.

GPT-5.5 bukan AI yang lebih cepat secara kuantitatif saja. Ini AI yang berbeda secara kualitatif — satu yang bisa jadi partner berpikir di domain yang sebelumnya dianggap eksklusif milik human expertise.
OpenAI menyebut ini sebagai bukti bahwa GPT-5.5 membuka kapabilitas kategori baru, bukan hanya improvement inkremental atas model sebelumnya.
Sekarang pikirkan: apa dalam workflow kamu yang bisa memanfaatkan kemampuan reasoning di level ini? Itu starting point evaluasi yang paling jujur.
Siapa yang Harus Pakai GPT-5.5 — dan Siapa yang Sebaiknya Tunggu
Keputusan adopt GPT-5.5 sekarang atau tunggu tergantung dari satu pertanyaan sederhana: apakah use case kamu paling relevan dengan area yang paling banyak improve?
Langsung adopt GPT-5.5 jika kamu:
- Punya workflow coding intensif — 13 poin lebih di Terminal-Bench 2.0 vs model terbaik Anthropic adalah gap yang langsung terasa di agentic coding pipelines. Ini bukan marginal gain.
- Butuh long-context analysis — codebase besar, kontrak panjang, research docs. Peningkatan MRCR v2 dari 36.6% ke 74.0% artinya context retention yang benar-benar berbeda secara kualitatif.
- Bangun autonomous agents — SWE-Bench Pro 58.6% single-pass adalah benchmark ter-relevant untuk agentic use cases yang butuh task completion mandiri tanpa loop human review terus-menerus.
Pertimbangkan tunggu jika:
- Kamu sudah lock in kontrak API jangka panjang yang renew di Q3 2026 — eval ulang saat kontrak habis, bukan paksa migrasi di tengah jalan.
- Use case kamu tidak compute-heavy: Q&A sederhana, summarization pendek, atau chat umum. GPT-5.4 masih lebih dari cukup dan tidak worth switching cost-nya sekarang.
Satu langkah praktis sebelum migrasi full:
Benchmark GPT-5.5 di satu workflow yang paling sering kamu jalankan — bukan benchmark sintetis, tapi task nyata dari pekerjaan harian kamu. Compare output quality, jumlah iterasi yang dibutuhkan, dan total token consumed. Data itu yang akan jawab pertanyaan lebih akurat dari benchmark manapun.
FAQ: GPT-5.5
Apa bedanya GPT-5.5 dengan GPT-5.4?
GPT-5.5 adalah base model pertama yang di-retrain penuh sejak GPT-4.5, sementara GPT-5.0 sampai 5.4 adalah post-training iteration dari fondasi yang sama. GPT-5.5 punya architecture baru, membawa peningkatan besar di agentic coding (82.7% Terminal-Bench), long-context retention (74.0% MRCR v2 di 1M token), dan scientific reasoning — bukan hanya versi yang lebih di-fine-tune.
Apakah GPT-5.5 lebih mahal dari GPT-5.4?
Tidak. Berdasarkan data LLM-Stats 2026, pricing API GPT-5.5 setara dengan GPT-5.4. Model yang lebih efisien dan butuh lebih sedikit iterasi untuk output yang benar membuat total cost per task bisa lebih rendah, meski kecerdasannya lebih tinggi secara keseluruhan.
Apakah GPT-5.5 tersedia untuk umum?
Ya. GPT-5.5 tersedia via API OpenAI sejak tanggal rilis 23 April 2026. ChatGPT users dengan plan Plus dan Pro mendapatkan akses bertahap dalam minggu yang sama setelah rilis resmi.
Seberapa baik GPT-5.5 dibanding model lain di 2026?
Dalam 24 jam setelah rilis, GPT-5.5 capai skor 60 di Artificial Analysis Intelligence Index dan ranked #2 dari 115 model di BenchLM dengan skor 93/100. Di agentic coding, GPT-5.5 unggul lebih dari 13 poin atas Claude Opus 4.7 di Terminal-Bench 2.0 — benchmark yang paling relevan untuk real-world developer use cases.
Coba GPT-5.5 via API sekarang — benchmark di satu workflow nyata kamu dan lihat sendiri selisihnya.
Atau simpan guide ini untuk referensi sebelum evaluasi AI stack atau tooling kamu berikutnya.