AI Safety Washing: Kenapa Perusahaan AI Butuh Kamu Takut
By Ali Sadikin Ma · · Updated
Category: Technology

Narasi kiamat AI ditulis oleh perusahaan yang menjual AI ke kamu.
Pikir sebentar.
Perusahaan yang paling sering bilang "AI bisa musnahkan umat manusia" adalah perusahaan yang sama yang jual produk AI ke perusahaan Fortune 500. Yang minta regulasi ketat di panggung publik, tapi terbang ke Brussels untuk lobi agar regulasinya... tidak terlalu ketat.
Industri punya nama untuk taktik ini: AI safety washing. Dan ini bukan teori konspirasi—ini adalah catatan bisnis yang bisa lo verifikasi sendiri.
Dan ada tiga hal yang perlu lo tahu sekarang:
Siapa yang sebenarnya diuntungkan dari rasa takutmu terhadap AI? Apa yang OpenAI, Anthropic, dan Google punya kesamaan—selain produk AI yang mereka jual? Dan bagaimana perusahaan yang paling terkenal karena safety justru menjadi skandal safety terbesar di 2026?
Anthropic, salah satu pemain utama narasi ini, sudah raise $7.3 miliar—sebagian besar di atas fondasi pesan safety-first dan positioning sebagai AI yang “bertanggung jawab.” (AI Business Review, 2026)
Tapi ini yang tidak diceritakan dalam headline-headline itu:
Rasa takutmu itu valid. Tapi sumber ketakutan itu perlu diperiksa lebih teliti dari yang pernah lo lakukan sebelumnya.
Cerita yang Sudah Kita Percaya: Doom Narrative dan Siapa yang Merumuskannya
Tidak satu pun perusahaan AI besar mendapat nilai di atas D dalam perencanaan Existential Safety, menurut Future of Life Institute AI Safety Index 2025—meski semua berlomba menuju AGI dalam satu dekade. Di saat bersamaan, CEO perusahaan yang sama mendominasi headline dengan peringatan risiko peradaban. Dua sinyal berlawanan berjalan beriringan.
Perusahaan AI terbesar dunia sudah memberi tahu kita bahwa AI berpotensi mengancam peradaban. CEO Anthropic bicara tentang “risiko eksistensial” dalam wawancara di media-media terkemuka. Sam Altman bersaksi di Kongres Amerika tentang teknologi yang “bisa sangat berbahaya.” Para pemimpin ini bukan orang sembarangan—mereka adalah figur paling berpengaruh di industri paling bernilai di planet ini.
Dan kita percaya.
Karena siapa yang mau meremehkan peringatan dari orang yang membangun teknologinya sendiri? Kalau orang yang membuat AI bilang itu berbahaya, pasti itu serius, kan?
Masuk akal. Sangat masuk akal—sampai lo melihat datanya secara langsung.
Nilai D dari Future of Life Institute itu bukan kecelakaan. Setiap perusahaan di daftar itu punya tim safety, ada yang ratusan orang. Mereka punya budget miliaran. Tapi tidak ada yang bisa menunjukkan rencana terverifikasi untuk menghentikan model mereka sendiri kalau benar-benar menjadi ancaman.
Itu bukan kontradiksi yang terjadi karena kecerobohan. Kontradiksi itu terjadi karena ada insentif di baliknya.
Tapi sebelum kita buka insentifnya, ada yang perlu lo lihat dulu:
Perilaku nyata perusahaan-perusahaan ini. Bukan press release. Bukan keynote speech. Tindakan nyata yang mereka ambil ketika tidak ada kamera.
Celah dalam Cerita: Ketika Fakta Tidak Cocok dengan Narasi AI Safety Washing
Pada Februari 2026, CNN Business melaporkan bahwa Anthropic menghapus klausul wajib pause-training dari kebijakan safety internal mereka—keputusan langsung akibat tekanan kompetitif. Ini adalah perusahaan yang paling keras bicara tentang risiko eksistensial AI. Dan mereka memilih kecepatan di atas klausul keselamatan yang mereka sendiri buat.
Kalau perusahaan AI benar-benar takut dengan risiko eksistensial yang mereka gembar-gemborkan, ada satu hal logis yang harus dilakukan: memperlambat. Tapi bukti di atas mengatakan sebaliknya—dan bukan hanya satu kali.
Di tengah konteks yang sama, pada Oktober 2025, David Sacks—mantan penasihat AI Gedung Putih yang pernah duduk langsung di ruangan kebijakan—secara terbuka menyebut Anthropic sedang “menjalankan strategi regulatory capture yang sophisticated, berbasis fear-mongering.” Ini bukan opini dari blogger pinggiran. Ini dari orang yang melihat prosesnya dari dalam.
Lalu ada memo internal OpenAI yang bocor ke AndroidHeadlines (2026). Dalam memo itu, tim OpenAI menyebut kompetitor utamanya membangun seluruh brand “di atas rasa takut, pembatasan, dan ide bahwa sekelompok kecil elit yang harus kontrol AI.”
Menarik sekali, kan?
Kompetitor menuduh kompetitor melakukan hal yang persis sama. Itu bukan karena salah satu jujur dan yang lain tidak. Itu karena AI safety washing—menggunakan retorika keselamatan sebagai alat branding dan strategi bisnis, bukan sebagai komitmen operasional yang nyata—sudah menjadi praktik standar di seluruh industri. Bukan satu perusahaan, tapi ekosistem.
Dan kalau lo penasaran siapa yang benar-benar menang dari situasi ini, playbooknya jauh lebih rapi dan sistematis dari yang lo bayangkan.
Playbook Asli: Bagaimana Rasa Takut Jadi Strategi Bisnis AI
Anthropic raise $7.3 miliar. Ingat angka itu.
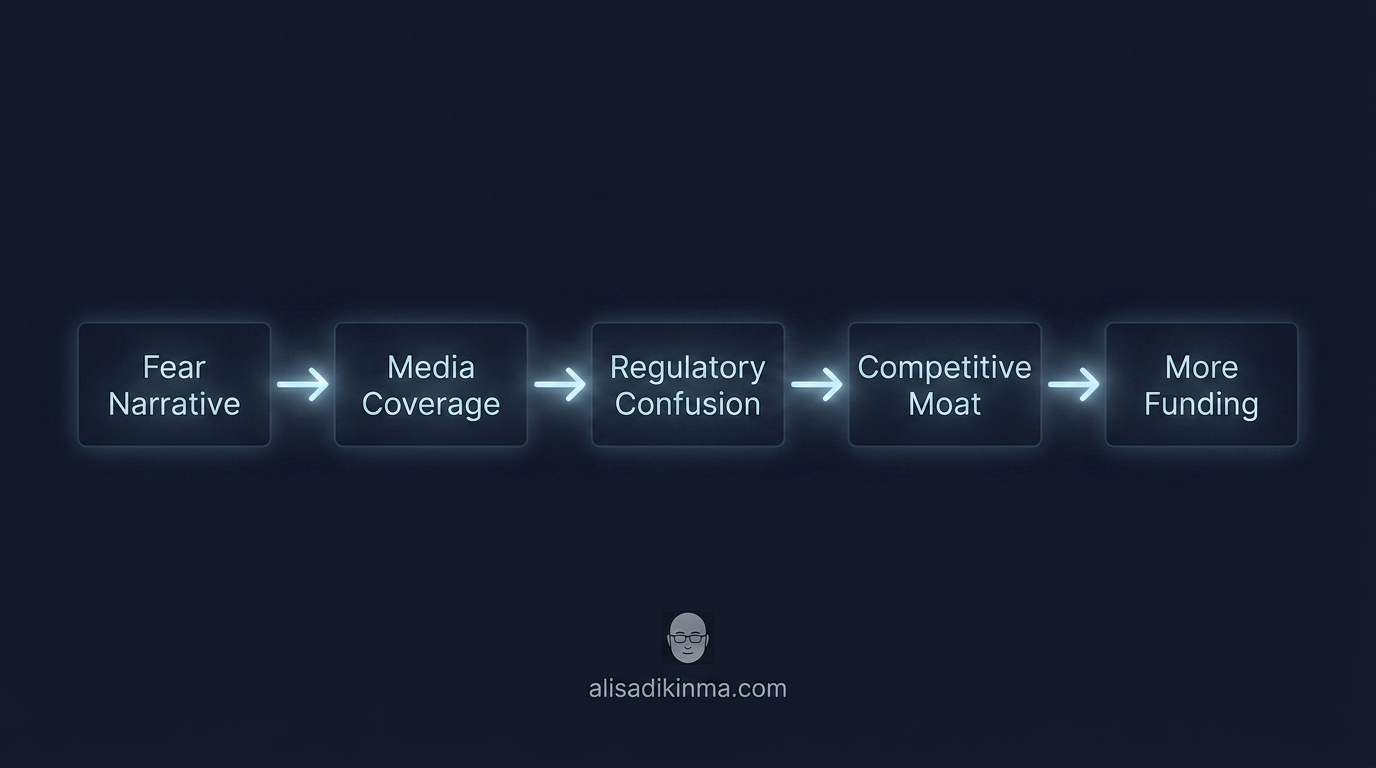
Sekarang tanya: kenapa investor kelas dunia mengeluarkan uang sebesar itu untuk perusahaan yang produk intinya chatbot dan API—kategori yang sudah penuh sesak dengan kompetitor? Jawabannya bukan semata karena produknya lebih baik dari yang lain. Jawabannya adalah karena narasi AI safety washing menciptakan competitive moat yang sangat sulit ditembus—jika publik percaya bahwa AI tanpa pengawasan ketat adalah ancaman, maka satu-satunya perusahaan yang “bertanggung jawab” adalah perusahaan yang sudah terpercaya secara publik. Dan kepercayaan itu dibangun dengan satu cara: membuat orang takut, lalu menawarkan diri sebagai perlindungan.

Ini adalah playbook empat langkah yang sudah terbukti berhasil:
Langkah 1 — Amplify the fear. CEO dan peneliti senior berbicara tentang risiko eksistensial di forum global—Davos, Capitol Hill, Konferensi PBB. Headline besar, coverage masif dari media arus utama. Dalam beberapa siklus berita, publik mulai percaya bahwa AI memang ancaman peradaban yang nyata dan mendesak.
Langkah 2 — Position yourself as the responsible actor. “Kami sadar akan risikonya—itulah kenapa kami hadir. Untuk memastikan AI berkembang dengan aman, tidak seperti perusahaan lain.” Safety jadi branding utama, bukan operasi internal yang bisa diaudit. Manifesto panjang. Keynote berapi-api. Safety teams yang foto-fotoin untuk press release.
Langkah 3 — Capture regulation. AlgorithmWatch (2025) mendokumentasikan bagaimana Presiden Komisi Eropa secara langsung menggunakan framing “existential risk” yang berasal dari surat terbuka yang ditandatangani CEO OpenAI dan Anthropic—lalu setelahnya memuji “aturan sukarela” yang dirancang oleh Big AI sendiri, sekaligus mendorong pelemahan EU AI Act yang tadinya lebih ketat. Bukan kebetulan. Ini adalah hasil dari lobi sistematis selama berbulan-bulan yang dimulai dari frame ketakutan.
Regulasi yang terlihat “ketat”—tapi dirancang oleh perusahaan yang seharusnya diregulasi. Ini bukan bug dari sistem. Ini adalah fitur yang direncanakan.
Langkah 4 — Close the moat. Kompetitor kecil yang tidak punya resource untuk “safety theater” ini tersisih secara alami. Hanya pemain besar yang punya uang untuk audit mahal, sertifikasi mewah, dan lobi regulasi yang bisa bertahan di ekosistem yang mereka sendiri rancang aturannya.
Dan hasilnya adalah persis seperti yang diprediksi ArXiv (2025): narasi risiko eksistensial “mengalihkan perhatian publik dan regulasi dari konsentrasi kekuatan ekonomi dan komputasi nyata yang sudah membentuk ulang masyarakat global.”
Lo tidak diingatkan tentang bahaya hipotetis AI di masa depan yang jauh.
Lo dialihkan dari pertanyaan yang jauh lebih mendesak sekarang: siapa yang mengontrol infrastruktur AI global, dan apa yang mereka lakukan dengannya?
Apa Artinya Ini Buat Lo: Lo Bukan Target Audiens Peringatan Ini
Peneliti dari ArXiv (2025) menyimpulkan bahwa kita—pengguna biasa, jurnalis, dan bahkan regulator—bukan target utama peringatan AI ini. Target utamanya adalah narasi publik yang, kalau berhasil dibentuk, menguntungkan perusahaan yang paling banyak mendanai pesan tersebut. Lo bukan audiens. Lo adalah channel distribusinya.
Lo tidak naif karena takut. Strateginya dirancang oleh orang-orang yang sangat paham cara kerja rasa takut—dan cara menggunakannya untuk membangun bisnis bernilai miliaran dolar.
Tapi sekarang lo sudah tahu.
Narasi “AI akan musnahkan manusia” bukan peringatan tulus dari pihak yang tidak punya kepentingan—setidaknya bukan dari perusahaan yang paling keras mengatakannya. Ini adalah instrumen untuk mengontrol regulasi, memenangkan funding ronde berikutnya, dan mendefinisikan ulang siapa yang “layak dipercaya” di industri ini.
Coba pikir ini:
ArXiv (2025) menunjukkan bahwa framing ketakutan ini secara sistematis mengalihkan perhatian kita dari pertanyaan yang lebih konkret—siapa yang mengontrol infrastruktur AI global? Siapa yang memiliki data training dari miliaran percakapan kita? Siapa yang memutuskan model apa yang boleh ada dan tidak boleh ada di pasar?
Itu pertanyaan yang tidak pernah dijawab dalam konferensi safety AI yang disponsori oleh perusahaan AI itu sendiri.
Jadi:
Pikirkan headline AI terakhir yang membuat lo takut. Siapa yang menerbitkannya? Siapa yang dikutip sebagai sumber? Dan siapa yang mendanai publikasi atau lembaga penelitian yang menjadi sumbernya?
3 Cara Tercepat Membaca Klaim AI Safety Tanpa Jadi Korban
Perusahaan-perusahaan yang menguasai narasi AI safety washing ini butuh satu hal dari lo: ketidakmampuan lo membedakan mana peringatan tulus, mana strategi bisnis yang dikemas sebagai kepedulian. Berikut tiga cara lo bisa memproteksi diri—masing-masing butuh kurang dari 60 detik per klaim yang lo temui.
1. Cek apakah mereka memperlambat atau mempercepat
Apa: Kalau perusahaan AI genuinely takut dengan risiko yang mereka klaim, tindakan paling logis adalah memperlambat—bukan mempercepat—deployment model baru mereka ke publik.
Bagaimana: Setiap kali lo membaca CEO AI bicara tentang risiko eksistensial, buka tab baru dan cari berita terbaru tentang product launch, funding round, atau pengumuman kecepatan pelatihan model mereka. Tanya satu pertanyaan sederhana: apakah mereka pause atau justru push lebih agresif dari sebelumnya? Jawaban itu lebih jujur dari apapun yang mereka katakan di panggung.
Contoh: Anthropic secara konsisten menjadi suara paling keras tentang AI safety di publik. Tapi CNN Business melaporkan (Februari 2026) bahwa mereka justru menghapus klausul pause-training dari kebijakan internal mereka—klausul yang harusnya menghentikan mereka kalau model sudah terlalu powerful untuk dikontrol—karena tekanan kompetitif. Retorika dan aksi berlawanan arah secara langsung.
Outcome: Lo akan langsung bisa membedakan perusahaan yang genuinely cautious dari yang menjual narasi cautious sambil berlari sekencang mungkin. Bedanya terlihat jelas dalam tiga menit riset sederhana—tanpa perlu baca satu pun safety whitepaper mereka.
2. Audit apakah aksi mereka cocok dengan retorika safety-nya
Apa: Komitmen safety yang nyata tercermin dalam keputusan operasional internal—bukan dalam statement publik, manifesto panjang, atau jumlah karyawan di tim safety mereka.
Bagaimana: Cari insiden keamanan aktual yang melibatkan perusahaan tersebut—bukan “potential risks” yang mereka sendiri ceritakan dalam blog post dan podcast, tapi breach dan kegagalan nyata yang dilaporkan oleh pihak ketiga yang tidak punya kepentingan finansial dengan mereka.
Contoh: Pada April 2026, Anthropic mengalami Mythos AI model breach. Menurut AI Business Review, insiden ini “memvalidasi kritik bahwa perusahaan AI melebih-lebihkan risiko model untuk menghasilkan publisitas, sambil tidak cukup berinvestasi dalam security hygiene dasar.” Satu breach yang terdokumentasi lebih informatif dari seratus safety whitepaper yang ditulis oleh tim marketing mereka sendiri.

Outcome: Lo punya cara kerja yang konkret untuk menilai klaim safety dengan bukti operasional—bukan retorika. Dan metode ini berlaku untuk perusahaan AI mana pun, bukan hanya Anthropic atau OpenAI.
3. Ikuti uangnya, bukan kata-katanya
Apa: Struktur funding, investor, dan model bisnis sebuah perusahaan AI lebih jujur tentang prioritas mereka daripada apapun yang tertulis dalam manifesto mereka tentang keselamatan.
Bagaimana: Cek tiga hal: siapa investor mereka dan apa ekspektasi return-nya, apa model bisnis inti mereka dan siapa pelanggan terbesarnya, dan siapa yang paling diuntungkan jika regulasi AI mengambil bentuk persis seperti yang mereka advokasi. Kalau jawabannya konsisten mengarah ke mereka sendiri—lo sudah tahu dinamika apa yang sedang berjalan.
Contoh: Anthropic raise $7.3 miliar sebagian besar di atas branding safety-first (AI Business Review, 2026). Narrative AI safety washing bukan hanya strategi untuk memenangkan opini publik—ini adalah fundability strategy yang terukur. Investor kelas dunia berani bayar premium untuk perusahaan yang terlihat “bertanggung jawab” di mata regulator karena itu mengurangi risiko regulasi bagi portofolio mereka.
Outcome: Setiap kali lo membaca pernyataan “kami peduli keamanan AI,” lo sekarang punya kerangka pikir untuk bertanya: apakah ini komitmen operasional yang bisa diaudit, atau iklan yang ditujukan kepada regulator dan investor untuk tujuan finansial yang sangat spesifik?
FAQ: Pertanyaan yang Muncul Setelah Baca Ini
Apakah rasa takut kita terhadap AI memang cuma produk yang dijual?
Tidak sepenuhnya. Ada peneliti AI yang genuinely khawatir tentang risiko jangka panjang, dan kekhawatiran itu valid secara ilmiah. Masalahnya adalah perusahaan yang paling keras menggemakan ketakutan itu adalah perusahaan yang paling banyak untung dari ketakutan tersebut. Dua hal bisa benar sekaligus: risikonya nyata, dan narasi tentang risiko itu dimanipulasi untuk kepentingan bisnis dan AI safety washing yang sistematis di tingkat industri.
Apakah Anthropic lebih buruk dari OpenAI dalam hal ini?
Keduanya bermain di game yang sama—bedanya hanya positioning brand. OpenAI sendiri, dalam memo internal yang bocor ke AndroidHeadlines (2026), menuduh Anthropic membangun seluruh bisnisnya “di atas rasa takut.” Artinya pemain utama industri ini pun mengakui bahwa AI safety washing adalah strategi nyata yang dipakai—mereka hanya menyalahkan kompetitor, sambil melakukan hal yang sama.
Bagaimana perusahaan yang paling keras bicara safety bisa jadi kontroversi safety terbesar?
Karena “safety” sebagai brand dan “safety” sebagai operasi adalah dua hal yang sangat berbeda. Anthropic Mythos breach (April 2026, AI Business Review) terjadi bukan karena ada gap nyata antara retorika safety publik mereka dan investasi aktual dalam keamanan operasional sehari-hari. Ketika brand utamamu adalah safety, breach bukan hanya masalah teknis—ini adalah krisis identitas yang mengekspos jarak antara narasi dan realita.
Saatnya Lo Jadi yang Tahu Duluan
Narasi kiamat AI ditulis oleh perusahaan yang menjual AI. Sekarang lo tahu cara membaca penulisnya.
Share artikel ini — kebanyakan orang di network lo masih percaya kebalikannya, dan mereka layak tahu.
Atau, simpan untuk next time seorang CEO tech memperingatkan kamu bahwa AI akan mengakhiri peradaban—artikel ini akan mengubah cara lo membaca semua itu selamanya.