GPT-5.5: OpenAI Didn't Update — They Rebuilt It from Scratch
By Ali Sadikin Ma · · Updated
Category: Technology

GPT-5.5 isn't a new version. It's a model built from scratch.
On April 23, 2026, OpenAI released GPT-5.5. Within the first 24 hours, it shot straight to the top of the Artificial Analysis Intelligence Index with a score of 60 — beating everything that came before it.
But that's not what makes it different.
What makes it different is why this happened.
Every previous GPT-5 model — from 5.0 to 5.4 — was built on the same foundation. Post-training iteration. Fine-tuning. Alignment. But the foundation itself has been identical since GPT-4.5. Every "upgrade" released over the past two years was basically the same model with new patches on top.
GPT-5.5? OpenAI threw all of that out.
Started from scratch. New architecture. New training data. New foundation. This is the first time since GPT-4.5 that they've actually retrained the base model from the ground up — and the results are giving competitors a headache.
But there's one question that hasn't been answered:
Does this rebuild from scratch actually feel different in the real world, or is it just benchmark numbers that don't matter to most users?
And there's one thing that's even more surprising than all those benchmarks:
GPT-5.5 just helped scientists prove a mathematical theorem that humans have been chasing for over 90 years.
That's not a marketing claim. That's an official research announcement from OpenAI itself.
Let's break it down one by one.
1. OpenAI Ditched the Old Foundation — GPT-5.5 Starts from Zero
GPT-5.5 is the first base model to be fully retrained since GPT-4.5 — meaning every model from GPT-5.0 through 5.4 was a post-training variation of the same foundation. GPT-5.5 has a completely new architecture, and the results show immediately: BenchLM gave it a score of 93/100 in its first provisional evaluation, ranked #2 out of 115 models they track.
Not #2 among new 2026 models. #2 out of every model that's ever existed.
Why does this matter?
Here's the analogy: post-training can make a model smarter, but there's a limit. You can fine-tune a fish until it navigates water more efficiently — but it's still a fish. Retraining the base model means you're changing its DNA from the ground up.
Every GPT-5 from version 5.0 to 5.4 was a fish that got better at swimming. GPT-5.5 is a different species.
This is official confirmation from OpenAI: this model isn't an iteration of the existing GPT-5 series — it's a new foundation that'll serve as the base for the next generation.
The question is: where does the difference hit hardest for day-to-day work?
2. GPT-5.5 Writes Code Like a Senior Engineer, Not a Chatbot
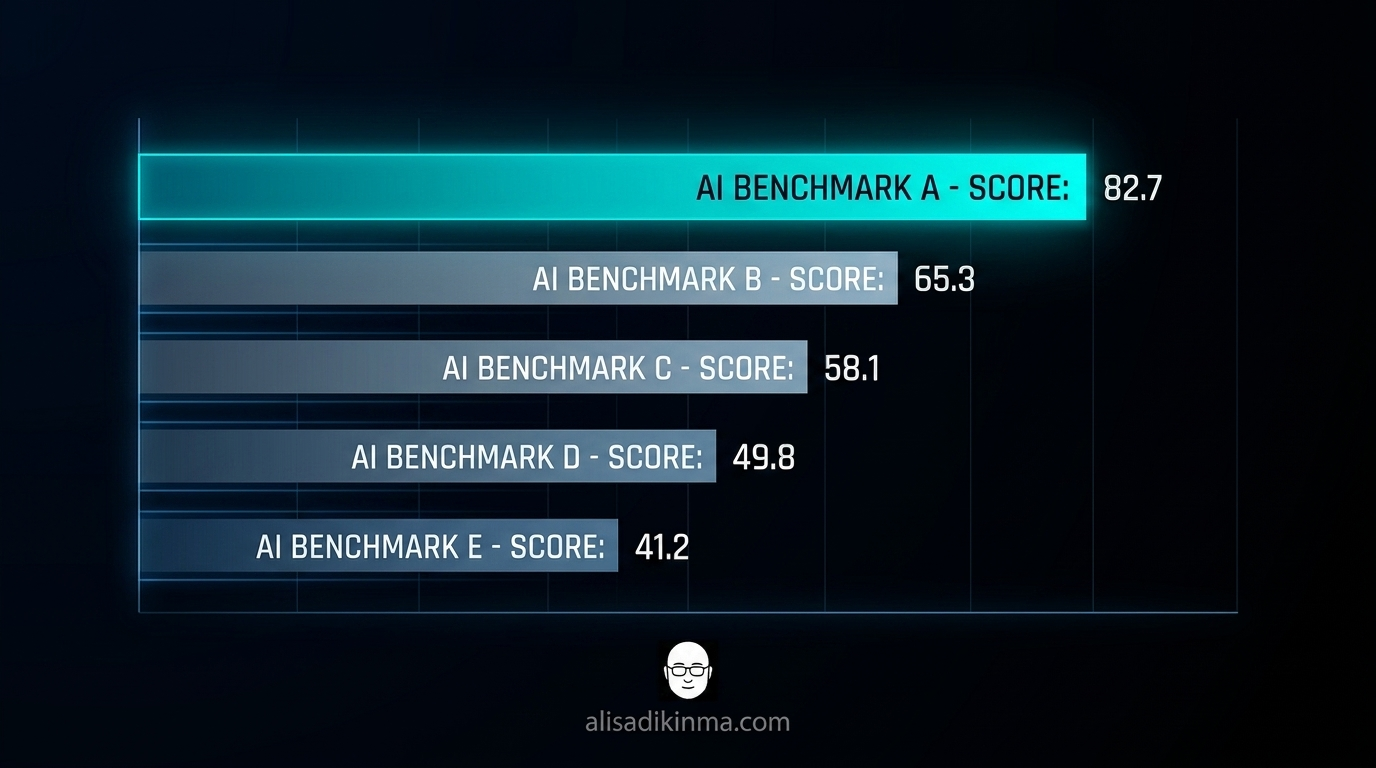
GPT-5.5 hit 82.7% on Terminal-Bench 2.0 — a benchmark that measures agentic coding in a real terminal environment, not a simulated sandbox. Claude Opus 4.7, Anthropic's best model right now, scored 69.4% on the same test. That's a 13-point gap. In the world of AI benchmarks, that's not small.
But what does Terminal-Bench 2.0 actually measure?
Not syntax completion. Not simple autocomplete. The model has to:
- Read and interpret error logs from a real terminal
- Debug multi-file projects without guidance from a human
- Write code that runs immediately — not code that needs to be edited twice
GPT-5.5 doesn't just suggest code. It executes end-to-end.
Here's how to use it right now:
Connect GPT-5.5 via API to your IDE — Cursor, VS Code with the OpenAI extension, or GitHub Copilot that already supports custom API endpoints. Assign complete tasks, not small sub-tasks. Concrete example: "Refactor this authentication module to support OAuth 2.0 and add unit tests" — not "Write a function for refresh token."
The results, based on independent CodeRabbit 2026 benchmarks: GPT-5.5 outperforms all previous models on realistic debugging tasks. Developers using agentic coding workflows can expect real time savings in debugging and refactoring cycles — especially for bugs that require reading many files at once.
But the coding capability is just part one. There's one upgrade that matters more for all use cases that need long context...
3. 1 Million Token Memory — and This Time It Actually Works
GPT-5.5 hit 74.0% on the MRCR v2 benchmark at a 1 million token context window. GPT-5.4 scored 36.6% on the same test. From 36.6% to 74.0% — more than double in a single model generation, according to official OpenAI 2026 data.
MRCR v2 isn't a simple test.
This benchmark doesn't measure whether a model "can" receive 1 million tokens. It measures whether the model can recall and use information from token 50,000 while processing token 900,000.
The difference is crucial:
GPT-5.4 can receive 1M tokens. GPT-5.5 actually uses 1M tokens.
This matters for:
- Codebase review — the model can maintain context across the entire repo, not just the files currently open
- Multi-session agents — agents can hold state across long projects without losing context halfway through
- Document analysis — long contracts, research papers, or legal briefs can be analyzed end-to-end without the model "forgetting" what it read at the start
If you've ever been frustrated because AI agents go totally amnesiac after a long conversation — this is what fixes that.
4. One Benchmark That Has Developers Floored
GPT-5.5 hit 58.6% on SWE-Bench Pro — a benchmark that measures a model's ability to resolve real-world GitHub issues in a single pass, without human input. More than half of real bug reports from open-source repos can be resolved by GPT-5.5 on its own, according to OpenAI and CodeRabbit 2026 data.
This isn't a test of writing new code.
SWE-Bench Pro takes real bug reports from active repos, hands them to the model, and evaluates whether the fix actually solves the problem — not just compiles, but actually passes regression tests.
Here's how to integrate it into your workflow:
Build a simple automation script that passes issue title, description, and relevant file contents to GPT-5.5 via API. Ask the model to output three things: (1) root cause analysis in 3 sentences, (2) proposed fix with a diff ready to apply, (3) test cases that need to be updated or added.
Small teams or solo developers can assign GPT-5.5 to the bug triage pipeline. The model handles 58%+ of issues autonomously — you focus on review and high-complexity cases that need human judgment and specific domain knowledge.
The results are real: for a 2-week sprint with 30 open issues, a conservative estimate is 40-60% time savings on debugging based on CodeRabbit 2026 benchmarks. That's dozens of hours per sprint you can redirect to feature development.
And this is still in the "expected" domain — coding and debugging. There's one domain that nobody expected GPT-5.5 to go this far into...
5. Scientists Now Have a Research Partner That Never Sleeps
GPT-5.5 contributed to the discovery of a new proof pathway for the Ramsey numbers problem — a combinatorics problem that mathematicians have been chasing for over 90 years. Mark Chen, Chief Research Officer at OpenAI, told TechCrunch in April 2026 that GPT-5.5 "shows meaningful gains on scientific and technical research workflows" and has the potential to help in drug discovery.
Ramsey numbers aren't just any problem.
This problem has existed since 1930. The question sounds simple: how large does a mathematical structure have to be before a certain pattern inevitably appears within it? But the formal answer has been chased for nearly a century — by some of the greatest mathematicians who ever lived.
GPT-5.5 didn't solve this problem on its own.
But it became a collaborator that could explore the search space at speeds impossible for humans — helping OpenAI's research team discover a new proof pathway that had never been found before.
Mark Chen named drug discovery as the next area this capability could touch. If GPT-5.5's scientific reasoning is applied to compound screening or protein folding analysis, the implications go way beyond the world of AI productivity.
This closes the loop we opened at the start: GPT-5.5 isn't just a faster productivity tool. It's a research collaborator that can be part of real scientific discoveries.

6. The Enterprise AI Competition Just Leveled Up
68% of organizations are currently at an advanced stage of GenAI adoption, and OpenAI leads with 57% market share in model adoption, according to Futurum Group 2026. GPT-5.5 arrives right at the most competitive moment in enterprise AI adoption history — and it immediately changes the evaluation baseline.
What does that mean for teams evaluating their stack right now?
Vendors still offering GPT-5.4 or earlier models have an increasingly hard sell. A 13-point gap in agentic coding benchmarks isn't a number you can easily dismiss in a procurement cycle — especially if your engineering team has already seen the results in a pilot.
For engineering teams evaluating a new AI stack:
GPT-5.5 changes the baseline. Use cases that were "good enough" with GPT-5.4 may no longer be competitive — especially for agentic workflows, long-context processing, or intensive scientific reasoning.
But before you restart all your evaluations from scratch, there's one practical question that comes up most often:
If the model is way smarter, the tokens must be way more expensive?
7. Smarter, Same Tokens — Here's What You Need to Know
GPT-5.5 maintains token efficiency on par with GPT-5.4 at a higher intelligence level. Based on LLM-Stats 2026 data, GPT-5.5 API pricing is at the same level as GPT-5.4, while output quality per call improves meaningfully across all major benchmark categories.
This rarely happens in AI model cycles.
Typically: intelligence upgrade = cost spike per token. OpenAI is breaking that pattern with GPT-5.5.
Why can the total cost actually be lower?
Because a smarter model needs less back-and-forth to get to the right answer. Re-prompting decreases. Error correction decreases. Total tokens consumed per task can be lower — even though you're paying the same rate per token.
For teams optimizing AI spend: this isn't just "a better model at the same price." It's potentially higher ROI per API dollar — especially for workflows that have needed many iterations to get to usable output.
Bonus: The Math Problem Chased for Decades — There's Finally a Breakthrough
The Ramsey numbers problem has existed since 1930. For 96 years, the world's best mathematicians — at the most prestigious universities, with the best resources available — haven't been able to fully solve this problem.
GPT-5.5, as an active research collaborator, managed to contribute to the discovery of a new proof pathway that humans had never found before.
This closes the loop we opened at the beginning of this article.

GPT-5.5 isn't just a quantitatively faster AI. It's a qualitatively different AI — one that can be a thinking partner in domains previously considered exclusively the territory of human expertise.
OpenAI calls this proof that GPT-5.5 unlocks new category capabilities, not just incremental improvements over previous models.
Now think: what in your workflow could take advantage of reasoning at this level? That's the most honest starting point for your evaluation.
Who Should Use GPT-5.5 — and Who Should Wait
The decision to adopt GPT-5.5 now or wait comes down to one simple question: is your use case most relevant to the areas that improved the most?
Adopt GPT-5.5 right away if you:
- Have an intensive coding workflow — 13 points higher on Terminal-Bench 2.0 vs Anthropic's best model is a gap you'll feel immediately in agentic coding pipelines. This isn't a marginal gain.
- Need long-context analysis — large codebases, long contracts, research docs. The MRCR v2 improvement from 36.6% to 74.0% means context retention that's genuinely different in quality.
- Building autonomous agents — SWE-Bench Pro 58.6% single-pass is the most relevant benchmark for agentic use cases that need autonomous task completion without constant human review loops.
Consider waiting if:
- You're already locked into a long-term API contract that renews in Q3 2026 — re-evaluate when the contract ends, don't force a migration mid-stream.
- Your use case isn't compute-heavy: simple Q&A, short summarization, or general chat. GPT-5.4 is still more than enough and not worth the switching cost right now.
One practical step before a full migration:
Benchmark GPT-5.5 on one workflow you run most often — not synthetic benchmarks, but real tasks from your daily work. Compare output quality, the number of iterations needed, and total tokens consumed. That data will answer the question more accurately than any benchmark.
FAQ: GPT-5.5
What's the difference between GPT-5.5 and GPT-5.4?
GPT-5.5 is the first base model to be fully retrained since GPT-4.5, while GPT-5.0 through 5.4 were post-training iterations from the same foundation. GPT-5.5 has a new architecture, bringing major improvements in agentic coding (82.7% Terminal-Bench), long-context retention (74.0% MRCR v2 at 1M tokens), and scientific reasoning — not just a more fine-tuned version.
Is GPT-5.5 more expensive than GPT-5.4?
Nope. Based on LLM-Stats 2026 data, GPT-5.5 API pricing is on par with GPT-5.4. The more efficient model that needs fewer iterations to get the right output can make the total cost per task lower, even though the overall intelligence is higher.
Is GPT-5.5 available to the public?
Yes. GPT-5.5 is available via the OpenAI API since its release date of April 23, 2026. ChatGPT users on Plus and Pro plans get gradual access in the same week after the official release.
How does GPT-5.5 compare to other models in 2026?
Within 24 hours of release, GPT-5.5 hit a score of 60 on the Artificial Analysis Intelligence Index and ranked #2 out of 115 models on BenchLM with a score of 93/100. In agentic coding, GPT-5.5 leads Claude Opus 4.7 by more than 13 points on Terminal-Bench 2.0 — the most relevant benchmark for real-world developer use cases.
Try GPT-5.5 via API right now — benchmark it against one real workflow and see the difference for yourself.
Or save this guide for reference before your next AI stack or tooling evaluation.