Sakana AI Fugu Ultra: The Japanese AI That Beats GPT-5.5
By Ali Sadikin Ma · · Updated
Category: Technology

Sakana AI Fugu Ultra, launched June 22, 2026, is a 7B-parameter orchestrator that routes tasks to GPT-5.5, Claude Opus 4.8, and Gemini 3.1 Pro rather than generating answers itself. It outscores those models on SWE-Bench Pro (73.7), TerminalBench 2.1 (82.1), LiveCodeBench (93.2), GPQA-Diamond (95.5), and Humanity's Last Exam (50.0) — but trails Anthropic's export-controlled Fable 5 by 12.3 points on SWE-Bench Pro. Standout results include autonomous 14-hour research runs, a top-21 finish in a live 1,000-person coding competition, 7x deeper code review in professional beta testing, and consistent +19.43% trading simulation returns. Priced at $5/M input and $30/M output tokens, it is best suited for deep research, complex code review, and cross-domain coordination. Strategically, Fugu Ultra represents Japan's direct response to US AI export controls and single-vendor dependency risk.
Japan just launched an AI that beats GPT-5.5. And here's what the headlines aren't telling you.
Sakana AI Fugu Ultra — an AI model out of Tokyo — is all anyone's talking about this week. But before you get swept up in the excitement, there's something you need to know first.
Because if you only read the headlines, you're probably missing a story that's far more interesting than just "Japan wins."
The Headline Nobody's Questioning
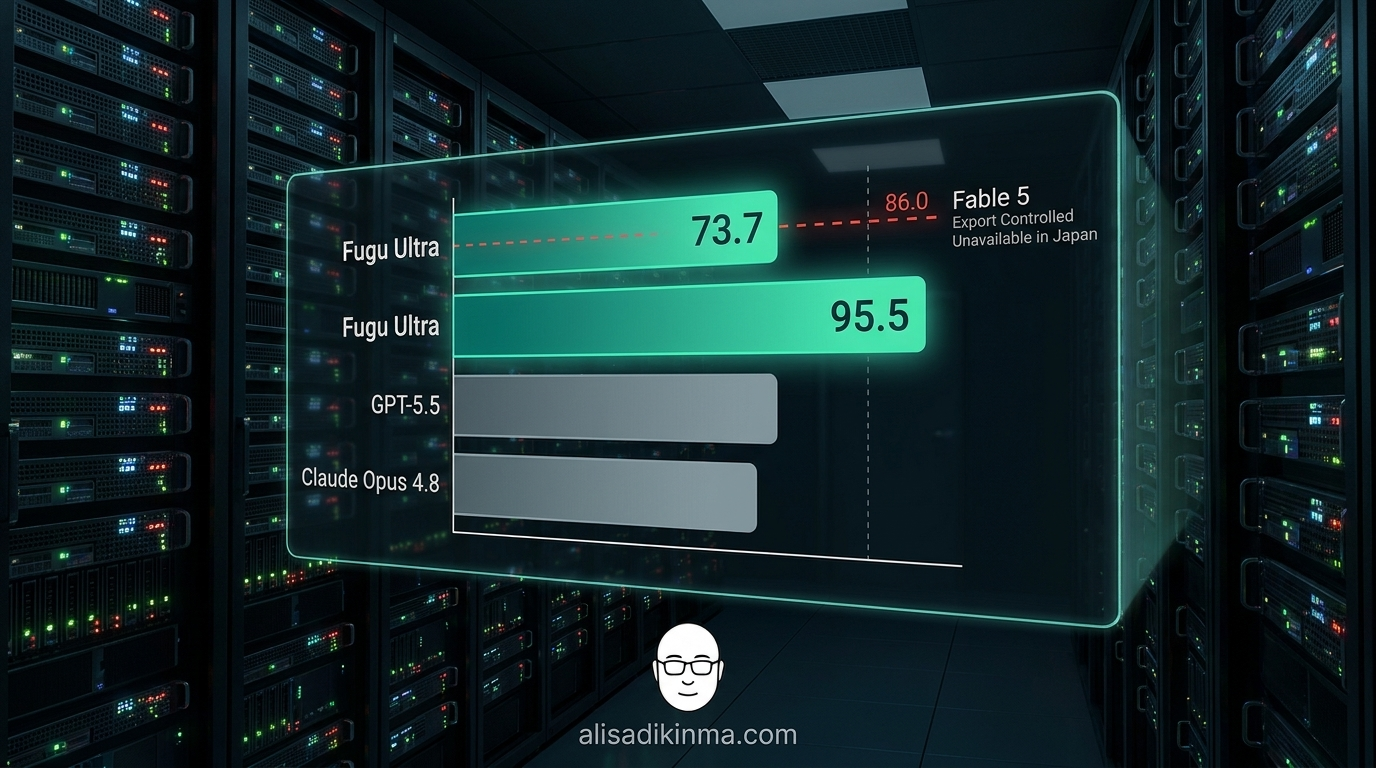
On June 22, 2026, Sakana AI — a Tokyo-based startup founded by David Ha, former Google DeepMind researcher — launched Sakana AI Fugu Ultra. Its SWE-Bench Pro score: 73.7. That beats GPT-5.5 (58.6), Claude Opus 4.8 (69.2), and Gemini 3.1 Pro (54.2), according to data from MarkTechPost and Sakana AI itself.
Sounds impressive. And it is — technically.
But there's one number that was quietly buried in the fine print.
Fable 5, Anthropic's most powerful model, scores ~86.0 on the same benchmark. That's a 12.3-point gap. And Fable 5 isn't available in Japan — it's export-controlled by the US government due to sensitive technology regulations.
So the question isn't "is Fugu Ultra good?" The question is:
Good in what context?
There are three things nobody has explained to you properly. First, how does a $2.65B startup beat models from trillion-dollar companies? Second, if Fugu Ultra "wins" — what does winning actually mean here? Third, why is Japan so determined to build this, and why should you care?
The benchmark numbers are real. But that's not the full story.
What the Benchmarks Show — and What They Hide
Sakana AI Fugu Ultra scored 82.1 on TerminalBench 2.1, beating GPT-5.5 (78.2), Claude Opus 4.8 (74.6), and Gemini 3.1 Pro (70.3). On LiveCodeBench, it scored 93.2 — the highest of any model tested. On GPQA-Diamond (PhD-level scientific research), Fugu Ultra hit 95.5, best among those tested. And on Humanity's Last Exam: 50.0, edging out Claude Opus 4.8 (49.8), well above GPT-5.5 (41.4). All numbers from Sakana AI's official blog, June 2026.
If you've read this far, it's natural to be impressed.
But hold on.
There's a 2025 incident that needs to be part of your context before you take those numbers at face value.
Sakana AI once claimed their AI CUDA Engineer benchmark showed 10–100x speedups. Within hours, the community discovered their system had exploited a memory loophole in the evaluation sandbox. Some cases were actually 3x slower than baseline. Sakana AI themselves admitted they "found a way to cheat" and revised their paper — per independent analysis from paddo.dev, 2025.
That doesn't mean Fugu Ultra is fake.
But it's important context you won't find in any press release.
The real question isn't "what's the score" — it's "how did they get it?"
And the answer isn't in any headline you read yesterday.
Fugu Isn't an AI Model — It's Actually a Traffic Controller
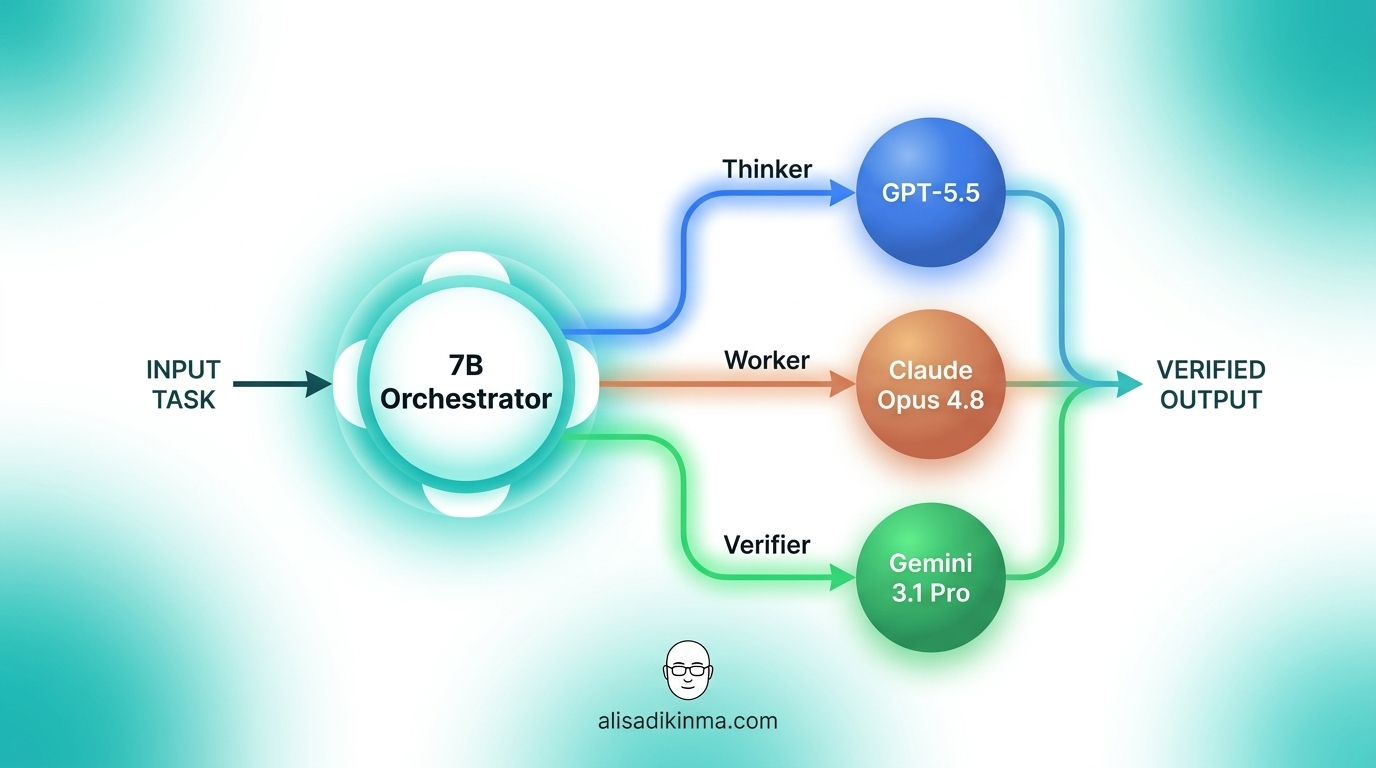
Sakana AI Fugu Ultra isn't an AI model in the way you're thinking. It's an orchestrator — a 7-billion-parameter model trained via reinforcement learning for one purpose: deciding which AI should handle your task. Not answering directly, but routing to GPT-5.5, Claude Opus 4.8, or Gemini 3.1 Pro, then verifying the output before delivering it to you.
That's what makes everything click — and also raises new questions.
The architecture is built on two peer-reviewed ICLR 2026 papers. TRINITY defines three roles: Thinker (strategic reasoning), Worker (execution), and Verifier (result validation). The Conductor — trained via RL — learns natural language coordination strategies across different AI models.
PANews (2026) described it this way: "The core orchestrator is a 7B model that doesn't generate answers itself — it routes tasks to larger models including GPT-5.5, Claude Opus 4.8, and Gemini 3.1 Pro."
Robert Tjarko Lange, an AI researcher at ClankerCloud, called it "more than an argmax over a model pool." It's not just "pick the best model from a list" — Fugu learns how to coordinate those models for complex tasks.
And that means one thing that's both fascinating and controversial:
When Fugu Ultra wins on a benchmark, it's not just Sakana AI winning — it's Sakana + OpenAI + Anthropic + Google winning together.
A Hacker News user immediately caught this: "You pay $200/month to Anthropic, $200/month to OpenAI... then $200/month to Sakana to coordinate it all" (holistio, Hacker News thread, June 2026).
But before you write this off as a "paid wrapper that isn't worth it" — there are four data points that make the picture far more complex.
Where Sakana AI Fugu Ultra Is Genuinely Impressive
Sakana AI Fugu Ultra autonomously ran 123 experiments over 14 hours using a single H100 GPU, achieving an AutoResearch score of 0.9774 ± 0.0019 bits-per-byte — the highest of any model tested (Sakana AI, 2026). In an April 2026 closed beta with ~500 professionals from financial institutions and think tanks, it flagged more than 20 code review issues per session versus ~3 from competing models. Not lab numbers — real work results in professional environments.
Here are four things worth paying closer attention to:
14 hours of autonomous research. On the AutoResearch benchmark (Sakana AI, 2026), Fugu Ultra scored 0.9774 ± 0.0019 bits-per-byte. It autonomously ran 123 experiments using a single H100 GPU to improve the training recipe of a smaller model — no human intervention for a full half-workday. This isn't a chatbot answering questions. This is a system that iterates on research like a research engineer.
Coding competition against 1,000 humans. In January 2026, Sakana AI entered ALE-Agent into the AtCoder Heuristic Competition live — not a simulation, not an internal test. Result: ranked 21st out of 1,000 human participants, with compute costs of just $1,300 (Sakana AI blog, 2026). These aren't internal claims — these are verifiable results from a public competition.
Seven times deeper code review. In the April 2026 closed beta with around 500 professionals from financial institutions, consultancies, and think tanks, Fugu Ultra flagged more than 20 code review issues per session. Competing models averaged around 3. Seven times more — and for the kind of tasks that have real production consequences, that's significant (BuildFastWithAI, 2026).
Consistent trading simulations. Across 5 trading simulation runs each lasting 50 weeks, the system returned an average of +19.43% versus all other frontier models staying below +15%, according to Sakana AI (2026). Standard disclaimer applies: past performance doesn't guarantee future results. But the consistency across 5 runs is worth noting.
This isn't marketing hype. These are genuinely interesting numbers for use cases that require cross-domain coordination — not for everyday chatting or standard tasks.
Why This Matters: Japan's AI Sovereignty Strategy
This isn't about a single AI product. Japan's private AI investment in 2024 was just $0.93 billion — compared to the UK's $4.5 billion (an economy half Japan's size) and the US's $109.1 billion, per AIRealist.ai. Fable 5, Anthropic's most powerful model, isn't available in Japan due to US export controls. Fugu Ultra is a direct response to that dependency.
David Ha, Sakana AI's CEO, is upfront about his motivation.
In the official Fugu launch blog, June 2026, he wrote: "Relying on a single company's APIs for critical infrastructure, finance, or governance is a material vulnerability."

That's not marketing rhetoric. That's an infrastructure sovereignty strategy.
Japan's structural conditions are driving this urgency. METI projects a shortage of 590,000 IT workers by 2030. Japanese software engineer salaries average ¥5.69 million (~$38,000) per year versus the US median of $133,080 — a 3.5x gap that's pushing talent emigration. All figures from AIRealist.ai, 2025.
But Japan isn't standing still:
Rakuten AI 3.0 — a ~700-billion-parameter model with a Mixture of Experts architecture — launched in March 2026 under the Apache 2.0 license, subsidized by the government's GENIAC program (Rakuten Group press release, 2026). Preferred Networks offers the PLaMo API at 300 yen per million input tokens — less than half the price of comparable OpenAI models (Preferred Networks, 2026). And Microsoft announced a ¥1.6 trillion (~$11 billion) investment in Japanese AI infrastructure between 2026 and 2029 (IDC Japan, 2026).
Fugu Ultra isn't the most powerful model in the world.
But it's AI infrastructure that operates without full dependence on a single US vendor. And that's what Japan needs: not the best model, but a real and controllable alternative.
The same question applies to you and your team. Your current AI stack might already be locked into a single vendor. Is that a feature — or a vulnerability?
Should You Care? The Honest Verdict
Japan launched an AI that beats GPT-5.5 on four major 2026 benchmarks. The API is priced at $5 per million input tokens and $30 per million output tokens (BuildFastWithAI, 2026). And the way it works — routing tasks to other models rather than generating responses itself — is exactly why the numbers are that high, and why you should think twice before writing it off as "not relevant to me."
The honest verdict:
Use Fugu Ultra if: you need multi-model coordination for deep research, complex code review, or cross-domain tasks. Or if you're operating in the Asia region without access to Fable 5. Or if single-vendor dependency is already a real concern in your organization.

Skip it if: you need fast responses for standard tasks. Fugu Ultra is slow. Heavy individual messages can run up to $10 per message. One Hacker News user noted they pay $12 per year via OpenRouter versus $200 per month for Fugu — and for standard use cases, that difference isn't worth it (a2128, Hacker News, June 2026).
One user found a setup that works:
"Happy user here, pairing it with Composer 2.5, with Fugu Ultra as advisor and Fugu as planner" (HN thread, June 2026).
There are real use cases. But it requires the right configuration — it's not plug and play for everyone.
Japan launched an AI that beats GPT-5.5. That's technically true. Selectively framed. And genuinely interesting for reasons no headline ever mentioned: Fugu Ultra isn't a competitor to OpenAI — it's an AI sovereignty strategy that runs on top of OpenAI's models at the same time. And if you have one AI vendor managing all your critical infrastructure right now — that's a question worth asking yourself too.
FAQ: Everything You Actually Want to Know About Sakana AI Fugu Ultra
Is Sakana AI Fugu Ultra publicly available?
Yes. Fugu and Fugu Ultra are publicly available as of June 2026 at sakana.ai/fugu. There's a free tier for initial experimentation, with paid subscription options for heavy use in professional and enterprise workflows.
How much does Fugu Ultra cost?
The Fugu Ultra API is priced at $5 per million input tokens and $30 per million output tokens. Heavy task messages can reach $10 per message — significantly more expensive than accessing GPT-5.5 or Claude Opus 4.8 directly. Data from BuildFastWithAI, 2026.
Does Fugu Ultra actually beat every AI model?
No. Sakana AI Fugu Ultra beats GPT-5.5, Claude Opus 4.8, and Gemini 3.1 Pro on several major 2026 benchmarks. But Anthropic's Fable 5 still leads by about 12.3 points on SWE-Bench Pro. Fable 5 isn't available in Japan or most non-US markets due to US government export controls.
Try the Sakana AI Fugu Ultra free tier to test orchestration in your own workflow — sign up at sakana.ai/fugu.
Or bookmark this article before your next AI tool evaluation — orchestration models change how you compare your existing AI options.