The Most Powerful AI Model Isn't Always the One You Can Actually Use
By Ali Sadikin Ma · · Updated
Category: Technology

Chasing the most powerful AI model is the wrong strategy. Top frontier models now score within 0.4 points of each other on MATH-500, making benchmark differences statistically meaningless. Four real barriers block teams from using the best models: production cost explosions, rate limits, data privacy requirements, and restricted access (as with GPT-5.6 Sol). A 5-question framework — covering task complexity, cost per output, data sensitivity, latency tolerance, and open model viability — helps teams route intelligently. The recommended 3-tier stack uses Ollama/Groq for high-volume tasks, Mistral/DeepSeek for complex reasoning, and Claude/OpenAI only for truly critical work, cutting AI spend by 50–70% without sacrificing output quality.
GPT-5.6 Sol launched on June 26, 2026. But you still can't use it.
Access is limited exclusively to verified government partner organizations — no public waitlist, no self-registration option, no concrete timeline for general availability, according to TechTimes June 2026.
And if you're thinking about AI model selection for your team, this isn't just about which model is the most powerful. It's about which model you can actually use — right now, in production, with the budget you have.
Why do the most powerful AI models always have walls that are so hard to get past?
But here's what's even more interesting:
In Q1 2026, the top 15 frontier models all scored above 96% on MATH-500. The gap between them was just 0.4 points — with a 1.3-point run-to-run variance. Benchmark rankings at the top are statistically meaningless as a basis for model selection decisions, according to the LayerLens Q1 2026 Frontier Model Report.
If performance is nearly identical, why is your team still paying premium prices for frontier models?
And there's one question that almost never gets answered:
What framework do high-performing teams use for smart AI model selection — not the most powerful, but the most usable and business-profitable?
Why Everyone Is Still Chasing the Most Powerful AI Model
Teams chasing the most powerful AI model are usually operating on a flawed assumption: higher benchmarks mean better output. In Q1 2026, the top 15 frontier models all scored above 96% on MATH-500 with a gap of just 0.4 points — statistically meaningless as a decision basis, according to LayerLens. Yet closed models still dominated 80% of token usage and 96% of revenue across the OpenRouter platform from May–September 2025, according to an MIT Sloan study.
The instinct makes sense.
If the benchmark is higher, the output must be better. If the model is newer, the results must be more accurate. That logic is easy to follow — until you see the bill.
But here's what benchmarks never tell you:
Open models have already reached 89.6% of closed model performance at launch — and close the remaining gap in 13 weeks, down from 27 weeks the year before, according to the MIT Initiative on the Digital Economy 2025. The MMLU gap between open and closed models narrowed from 17.5 percentage points to just 0.3 points in a single year. But trust in brand names remains far stronger than actual ROI calculations.
And there are four concrete barriers making this problem worse.
4 Walls Standing Between You and the Right Model
Four concrete barriers prevent teams from using the right AI model: costs that explode in production, unplanned rate limits, data privacy constraints, and access restrictions imposed by safety frameworks. Forrester 2026 found that 70% of CIOs cite AI cost uncertainty as the number one barrier to adoption — ranking higher than technical constraints or talent gaps.
This isn't about your team lacking skill. It's about four real barriers that almost never make it into AI budget planning.
1. Cost Explosion
You think you've calculated your AI costs carefully. Then the production bill arrives.
$40 in dev, $680 in production. It's a pattern that repeats across teams — not a unique story. Why? Because the unit price per token is falling, but the tokens consumed per task are rising faster than the price is dropping. Total monthly bills keep climbing even as per-token costs keep falling, according to Artefact 2026.
2. Rate Limits
This barrier gets overlooked during planning — until you're already in production.
According to the Retool State of AI Report 2025, 62% of developers building LLM API applications cite rate limiting as their biggest operational challenge in production — ranking above latency and cost. There's no dedicated capacity reservation option on public APIs. When traffic spikes suddenly, your system queues up with no priority option.
3. Data Privacy
Sensitive data and cloud-based frontier models are fundamentally incompatible.
Health data, financial data, internal communications — all of it requires guarantees that data stays on your own servers. Closed models mean your data leaves your infrastructure. There's no middle ground for use cases like these.
4. Access Restrictions
And there's one barrier that almost no team plans for:
The most powerful frontier models are often not yet publicly accessible. GPT-5.6 Sol isn't the first and won't be the last. More than 12 AI companies have published Frontier AI Safety Frameworks with capability thresholds that can trigger access restrictions at any time, according to METR Common Elements of Frontier AI Safety Policies 2025. The model you're planning to use next month could suddenly become unavailable.
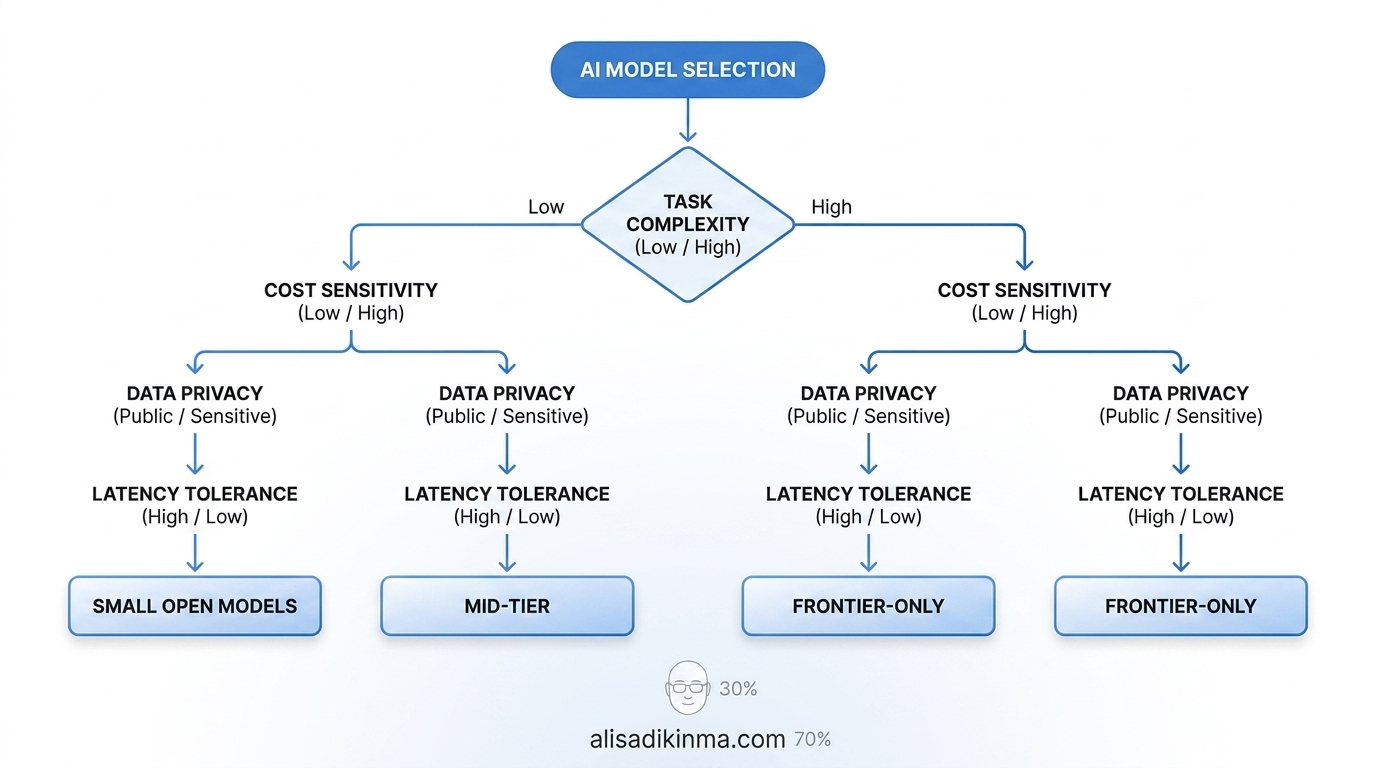
5 Questions High-Performing Teams Use for AI Model Selection

These five questions form the AI model selection framework that high-performing teams use for smart routing — cutting costs without sacrificing output quality. AlterSquare 2025 found that 85% of LLM API requests can be routed to fast, cheap models. Only 15% actually require frontier-scale capabilities.
Your team might be paying frontier prices for 85% of the work that doesn't need frontier capability.
1. How Complex Is This Task?
What you need to do: Classify tasks by the level of reasoning required — not by habit or the assumption that a more powerful model always produces better output for every type of work.
How to do it: Break down all of your team's AI tasks into three categories. Category A is formulaic, repetitive output — short summarization, formatting, classification, and tagging. Category B covers multi-step reasoning, complex content drafts, and structured data analysis. Category C is tasks requiring high nuance, deep creative problem-solving, or highly specific domain expertise. This mapping can be done with a simple spreadsheet: task column, category column, current model in use, actual monthly cost.
Real example: Engineering teams that understand AI unit economics use Groq and Ollama for Category A, DeepSeek and Mistral for Category B, and only reach for Anthropic Claude or OpenAI for business-critical Category C tasks. Their cost distribution is proportional to the value being generated — not spread evenly across all workloads.
Outcome: Proper routing based on task complexity can cut 50–70% of token spend without reducing the output quality experienced by end users.
2. What's a Reasonable Cost Per Output?
What you need to do: Calculate unit economics per output — not total budget. What does it cost to produce one unit of work your team needs? That number is the basis for decisions, not gut feelings about quality.
How to do it: Multiply the average tokens per request by the price per million tokens for the model you're using, then compare across your options. Start with this reference point: GPT-4-level performance is now available under $1 per million tokens — down from $30 in 2023, a 97% drop in three years, according to LLM Stats AI Trends June 2026. Then compare with open alternatives. MIT Sloan found that closed models are on average 87% more expensive ($1.86 vs. $0.23 per million tokens) compared to comparable open models for five consecutive months.
Real example: For article summarization averaging 500 tokens per request, a frontier model costs roughly $0.93 per 1,000 articles. A mid-tier open-source model produces comparable output at $0.12 per 1,000 articles. At a volume of 10,000 articles per month, that's a difference of more than $8,100 per month from a single workload alone.
Outcome: Clear visibility into what's worth paying a premium for — and what's burning budget without measurable return.
3. Can This Data Leave Your Servers?
What you need to do: This is a binary question. Sensitive data cannot be processed via cloud-based models — full stop. This isn't a technology choice; it's a compliance obligation that can't be compromised for any reason.
How to do it: Define your data classification levels before choosing a model. Create three classes: Public (safe to process via any API), Internal (requires encryption and audit trail), Confidential (must be self-hosted). For Confidential data, use open models deployed on your own infrastructure. Ollama and LM Studio enable running models locally with minimal setup. Open models now reach 89.6% of closed model performance at launch and close the gap within 13 weeks, according to the MIT Initiative on the Digital Economy 2025.
Real example: A healthcare company needing AI for patient data analysis has no choice but self-hosted open models. With LM Studio, they get sufficient performance while maintaining full compliance — and save 87% compared to closed alternatives that can't even legally be used for this use case.
Outcome: Compliance maintained and costs reduced at the same time. For sensitive data, open models aren't just the cheaper option — they're the only legally viable one.
4. How Much Latency Can You Tolerate?
What you need to do: Distinguish between tasks that need real-time responses and those that can run async. This determines your architecture — and the right model choice to go with it.
How to do it: Frontier models via public API have a P50 time-to-first-token of 200–600ms — not including queue delays from rate limits during high traffic, according to Spheron Blog 2026. Identify each task: is the user waiting for a real-time response, or can the result be delivered after processing completes? Tasks that can be batched asynchronously can use cheap, high-throughput models. Tasks requiring instant response need a lightweight self-deployed model or Groq LPU, specifically designed for fast inference with minimal latency.
Real example: A customer service chatbot needs real-time responses — it's a candidate for models deployed on your own infrastructure with Groq or Ollama. Email classification, content tagging, and daily report generation can all run in async batches outside peak hours, at 10x lower cost than processing them in real-time on a frontier model.
Outcome: More responsive user experience for tasks that truly need speed, with far lower cost for the majority of workloads that can run async.
5. Is an Open Model Good Enough for This Task?
What you need to do: Don't assume you need a frontier model until you've tested open alternatives. The capability gap is closing faster than most teams realize.
How to do it: Test open models first before committing to a closed model. Use Hugging Face — over 2 million models are available to try for free. The latest data: 3B–14B parameter models today are on par with 70B models from 12–18 months ago on targeted production tasks, according to Seldo.com 2026. DeepSeek offers benchmark performance comparable to Claude at 28x lower cost. Alibaba Qwen has been downloaded more than 1 billion times and accounts for more than 50% of all open model downloads globally as of January 2026 — this is no longer a niche market.
Real example: Developers switching from frontier models to Qwen for text generation report comparable output quality with 60–80% savings on monthly spend. For most content tasks, the output difference between open mid-tier and frontier models is indistinguishable to end users.
Outcome: More than enough capability for most tasks, at a fraction of the cost — with full control over your own infrastructure.
What a 3-Tier Model Stack Looks Like in Practice
A 3-tier AI stack divides models by actual need: lightweight models for high-volume tasks, mid-tier models for complex reasoning, and frontier models only for what's truly critical. LLM Stats AI Trends June 2026 noted that GPT-4-level performance is now available under $1 per million tokens — a 97% drop from $30 in 2023. But smart model selection isn't just about price — it's about matching capability to the actual demands of the task.
Here's the architecture that engineering teams serious about AI unit economics actually use:
Tier 1 — High Volume, High Speed: Ollama, Groq, LM Studio. For repetitive tasks — classification, formatting, short summarization, tagging. Lowest cost, lowest latency, right for 85% of existing workloads.
Tier 2 — Complex Reasoning: Mistral AI, Together AI, DeepSeek. For complex content drafts, multi-step analysis, and tasks requiring nuance. Mid-cost with solid capability for most demanding production needs.
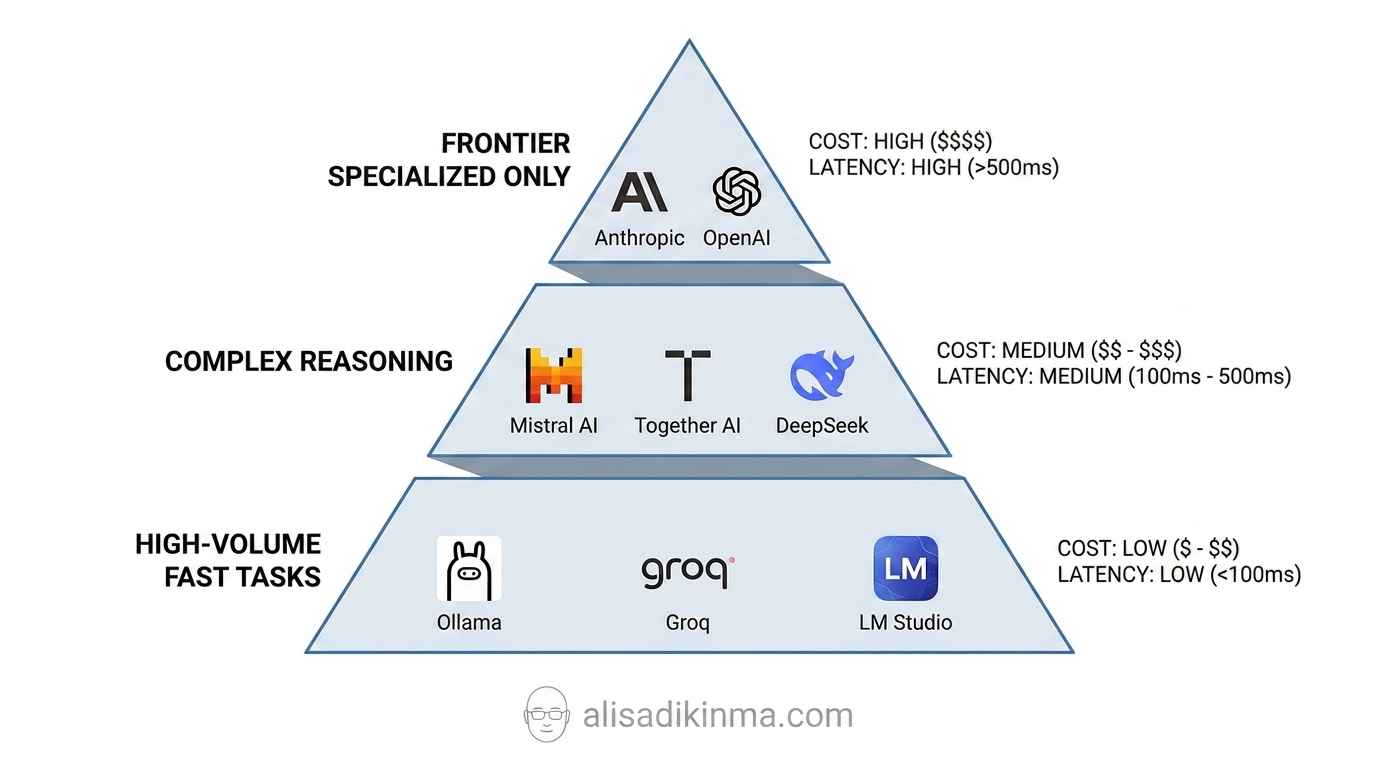
Tier 3 — Frontier, Used Sparingly: Anthropic Claude, OpenAI. Only for tasks that truly require state-of-the-art — high-level creative problem-solving, domain expert reasoning, or output going directly to premium clients.
And this isn't just theory.
According to AlterSquare AI Engineering Analysis 2025, for every $1 spent building an AI model, $5–10 must be spent making it production-ready — monitoring, integration, scaling, and reliability infrastructure. The wrong model choice isn't just expensive at runtime — it's expensive across the entire production lifecycle.
Teams building a 3-tier stack like this maintain output quality while significantly cutting AI spend — and have a stack that's far more resilient to price changes or access policy shifts from any single provider.
The Shift That Changes How You Ship AI
The most impactful shift in AI development isn't about the most powerful model — it's about smart AI model selection based on real tasks and unit economics that actually make sense. The MIT Initiative on the Digital Economy 2025 calculated that optimal reallocation of enterprise AI workloads from closed to open models could save $25 billion per year across the global AI economy. That 3.3% performance gap between the best closed and open models on LMSYS Arena — that's what you're paying 87% more to get, according to the Stanford HAI 2026 AI Index Report.
Remember GPT-5.6 Sol from the start of this article?
The most powerful AI model in existence right now — and you still can't use it. Not because your team isn't capable. But because this is the structural reality that will keep repeating with every next generation of frontier models.
Here's the real insight:
The next AI breakthrough isn't about the most powerful model. It's about the model you can actually ship — with a stack designed for real tasks, unit economics that make sense, and infrastructure control that doesn't depend on access decisions from a single provider.
Which workload on your team this week are you routing to a frontier model when a smaller model would be more than enough?
FAQ — Common Questions About AI Model Selection
Are open-source AI models good enough for production?
Yes, for most production tasks. Open-source AI models now reach 89.6% of closed model performance at launch and close the remaining gap within 13 weeks — down from 27 weeks the year before, according to the MIT Initiative on the Digital Economy 2025. The performance gap between the best open and closed models on LMSYS Arena is just 3.3% per Stanford HAI 2026 AI Index. For tasks requiring data privacy or high volume, open models aren't just the cheaper alternative — they're the smarter choice overall.
Why aren't AI benchmarks enough to choose the right model?
Because benchmarks measure controlled lab conditions, not real production environments. In Q1 2026, the top 15 frontier models all scored above 96% on MATH-500 with a gap of just 0.4 points — not statistically significant, according to LayerLens. Enterprise agentic AI systems show a 37% gap between lab benchmark scores and real deployment performance, with 50x cost variation for similar accuracy levels, according to Kili Technology AI Benchmarks Guide 2026.
Start routing smarter today — use the 5 questions above to audit one AI workload on your team this week. It takes less than 30 minutes, and the results will change how you see your team's AI spending.
Not ready to restructure your stack? Save this article for your next architecture review. The cost math will change how you look at AI model rankings forever.