AI Safety Washing: Why AI Companies Need You Scared
By Ali Sadikin Ma · · Updated
Category: Technology

The AI doom narrative is written by the companies selling AI to you.
Think about it for a second.
The companies that most often say "AI could destroy humanity" are the same ones selling AI products to Fortune 500 companies. They call for strict regulation on the public stage, then fly to Brussels to lobby for rules that are... not quite so strict.
The industry has a name for this tactic: AI safety washing. And this isn't a conspiracy theory — it's a business record you can verify yourself.
And there are three things you need to know right now:
Who actually benefits from your fear of AI? What do OpenAI, Anthropic, and Google have in common — besides the AI products they're selling? And how did the company most famous for safety end up becoming the biggest safety scandal of 2026?
Anthropic, one of the main players in this narrative, has raised $7.3 billion — much of it built on a safety-first message and positioning as the "responsible" AI company. (AI Business Review, 2026)
But here's what those headlines don't tell you:
Your fear is valid. But the source of that fear deserves more scrutiny than you've ever given it.
The Story We've Been Sold: The Doom Narrative and Who's Writing It
Not one major AI company scored above a D on Existential Safety planning, according to the Future of Life Institute AI Safety Index 2025 — even as all of them race toward AGI within a decade. At the same time, CEOs from those same companies dominate headlines with warnings about civilizational risk. Two opposing signals running side by side.
The world's biggest AI companies have been telling us that AI could threaten civilization. Anthropic's CEO talks about "existential risk" in interviews with major media outlets. Sam Altman testified to the US Congress about technology that "could be very dangerous." These leaders aren't random people — they're the most influential figures in the most valuable industry on the planet.
And we believed them.
Because who'd dismiss a warning from the people who built the technology themselves? If the people making AI say it's dangerous, that has to be serious, right?
Makes sense. It makes complete sense — until you actually look at the data.
That D grade from the Future of Life Institute isn't an accident. Every company on that list has a safety team — some with hundreds of people. They have billion-dollar budgets. But not one can show a verified plan to actually stop their own models if they became a genuine threat.
That's not a contradiction that happened by accident. It exists because there are incentives behind it.
But before we get into the incentives, here's what you need to see first:
The actual behavior of these companies. Not the press releases. Not the keynote speeches. The real actions they take when no cameras are rolling.
Cracks in the Story: When the Facts Don't Match the AI Safety Washing Narrative
In February 2026, CNN Business reported that Anthropic removed a mandatory pause-training clause from their internal safety policy — a decision directly driven by competitive pressure. This is the company that speaks loudest about AI's existential risks. And they chose speed over a safety clause they wrote themselves.
If AI companies genuinely feared the existential risks they trumpet, there's one logical thing to do: slow down. But the evidence above says the opposite — and this isn't a one-time thing.
In the same context, in October 2025, David Sacks — former White House AI advisor who sat in policy rooms directly — publicly called Anthropic out for "running a sophisticated regulatory capture strategy built on fear-mongering." This isn't some fringe blogger's opinion. This is from someone who saw the process from the inside.
Then there's the OpenAI internal memo that leaked to AndroidHeadlines (2026). In it, the OpenAI team described their main competitor as building their entire brand "on fear, restrictions, and the idea that a small elite group should control AI."
Interesting, right?
Competitors accusing competitors of doing the exact same thing. That's not because one is honest and the other isn't. It's because AI safety washing — using safety rhetoric as a branding tool and business strategy, not as a genuine operational commitment — has become standard practice across the entire industry. Not one company, but an ecosystem.
And if you're wondering who's actually winning from this situation, the playbook is far neater and more systematic than you'd think.
The Real Playbook: How Fear Became an AI Business Strategy
Anthropic raised $7.3 billion. Remember that number.
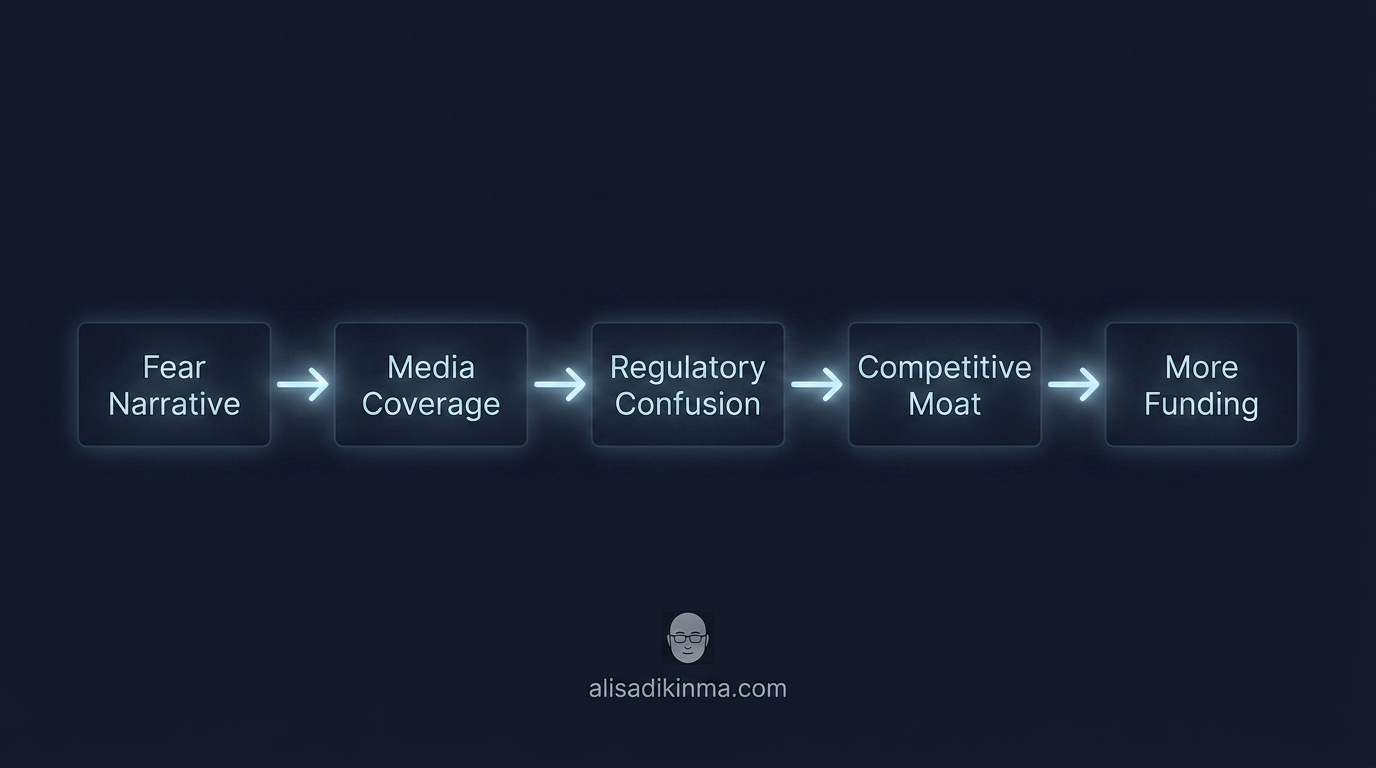
Now ask: why would world-class investors pour that kind of money into a company whose core products are chatbots and APIs — a category already crowded with competitors? The answer isn't just that their product is better. The answer is that the AI safety washing narrative creates a competitive moat that's nearly impossible to breach — if the public believes that unsupervised AI is a threat, then the only "responsible" company is the one the public already trusts. And that trust is built one way: make people afraid, then offer yourself as the protection.

Here's the four-step playbook that's proven to work:
Step 1 — Amplify the fear. CEOs and senior researchers talk about existential risks at global forums — Davos, Capitol Hill, UN Conferences. Big headlines, massive coverage from mainstream media. Within a few news cycles, the public starts believing AI really is a real and urgent threat to civilization.
Step 2 — Position yourself as the responsible actor. "We're aware of the risks — that's why we're here. To make sure AI develops safely, unlike other companies." Safety becomes the core brand, not an auditable internal operation. Lengthy manifestos. Fiery keynote speeches. Safety teams photographed for press releases.
Step 3 — Capture regulation. AlgorithmWatch (2025) documented how the President of the European Commission directly adopted the "existential risk" framing from an open letter signed by OpenAI and Anthropic CEOs — and then praised "voluntary rules" designed by Big AI itself, while pushing to weaken the EU AI Act that had originally been stricter. Not a coincidence. This is the result of months of systematic lobbying that began with the fear frame.
Regulations that look "strict" — but designed by the companies that were supposed to be regulated. This isn't a bug in the system. It's a planned feature.
Step 4 — Close the moat. Smaller competitors who don't have the resources for this "safety theater" get squeezed out naturally. Only the big players with money for expensive audits, fancy certifications, and regulatory lobbying can survive in an ecosystem they designed the rules for themselves.
And the result is exactly what ArXiv (2025) predicted: the existential risk narrative "diverts public and regulatory attention away from the real concentration of economic and computational power that has already reshaped global society."
You're not being warned about hypothetical AI dangers in the distant future.
You're being distracted from a far more pressing question right now: who controls global AI infrastructure, and what are they doing with it?
What This Means for You: You're Not the Target Audience of These Warnings
Researchers from ArXiv (2025) concluded that we — ordinary users, journalists, and even regulators — aren't the primary audience of these AI warnings. The primary target is the public narrative that, once successfully shaped, benefits the companies funding those messages the most. You're not the audience. You're the distribution channel.
You're not naive for being afraid. The strategy was designed by people who deeply understand how fear works — and how to use it to build billion-dollar businesses.
But now you know.
The "AI will destroy humanity" narrative isn't a sincere warning from parties with no stake in the game — at least not from the companies shouting it loudest. It's an instrument to control regulation, win the next funding round, and redefine who gets to be "trustworthy" in this industry.
Think about this:
ArXiv (2025) shows that this fear framing systematically distracts us from more concrete questions — who controls global AI infrastructure? Who owns the training data from billions of our conversations? Who decides which models get to exist in the market and which don't?
Those are the questions that never get answered at AI safety conferences sponsored by the AI companies themselves.
So:
Think about the last AI headline that scared you. Who published it? Who was cited as the source? And who funded the publication or research institution that sourced it?
3 Fastest Ways to Read AI Safety Claims Without Getting Played
The companies controlling the AI safety washing narrative need one thing from you: your inability to tell the difference between a genuine warning and a business strategy dressed up as concern. Here are three ways to protect yourself — each taking less than 60 seconds per claim you come across.
1. Check whether they're slowing down or speeding up
What: If an AI company genuinely fears the risks they claim, the most logical action is to slow down — not speed up — their deployment of new models to the public.
How: Every time you read an AI CEO talking about existential risk, open a new tab and search for the latest news about their product launches, funding rounds, or model training speed announcements. Ask one simple question: are they pausing or actually pushing more aggressively than before? That answer is more honest than anything they say on stage.
Example: Anthropic is consistently the loudest public voice on AI safety. But CNN Business reported (February 2026) that they actually removed the pause-training clause from their internal policy — the clause meant to stop them if a model became too powerful to control — due to competitive pressure. Rhetoric and action going in directly opposite directions.
Outcome: You'll immediately be able to tell apart companies that are genuinely cautious from those selling a cautious narrative while running as fast as they can. The difference shows up clearly in three minutes of simple research — no need to read a single one of their safety whitepapers.
2. Audit whether their actions match their safety rhetoric
What: Real safety commitment shows up in internal operational decisions — not public statements, lengthy manifestos, or headcount on their safety team.
How: Look for actual security incidents involving the company — not "potential risks" they describe themselves in blog posts and podcasts, but real breaches and failures reported by third parties with no financial stake in them.
Example: In April 2026, Anthropic experienced the Mythos AI model breach. According to AI Business Review, the incident "validated the criticism that AI companies overhype model risks for publicity, while underinvesting in basic security hygiene." One documented breach is more informative than a hundred safety whitepapers written by their own marketing team.

Outcome: You'll have a concrete way to evaluate safety claims with operational evidence — not rhetoric. And this method works for any AI company, not just Anthropic or OpenAI.
3. Follow the money, not the words
What: A company's funding structure, investors, and business model are more honest about their priorities than anything written in their safety manifesto.
How: Check three things: who their investors are and what their return expectations are, what their core business model is and who their biggest clients are, and who benefits most if AI regulation takes exactly the shape they're advocating for. If the answers consistently point back to themselves — you already know what dynamic is playing out.
Example: Anthropic raised $7.3 billion largely on safety-first branding (AI Business Review, 2026). The AI safety washing narrative isn't just a strategy for winning public opinion — it's a measurable fundability strategy. World-class investors pay a premium for companies that look "responsible" to regulators because it reduces regulatory risk for their portfolio.
Outcome: Every time you read the statement "we care about AI safety," you now have a framework to ask: is this an auditable operational commitment, or an ad targeting regulators and investors for very specific financial purposes?
FAQ: Questions That Come Up After Reading This
Is our fear of AI really just a product being sold to us?
Not entirely. There are AI researchers who genuinely worry about long-term risks, and those concerns are scientifically valid. The problem is the companies amplifying that fear the loudest are the ones who profit from it the most. Two things can be true at once: the risks are real, and the narrative about those risks is being manipulated for business interests and systematic AI safety washing at the industry level.
Is Anthropic worse than OpenAI at this?
They're both playing the same game — the only difference is brand positioning. OpenAI itself, in an internal memo that leaked to AndroidHeadlines (2026), accused Anthropic of building their entire business "on fear." That means the industry's key players acknowledge that AI safety washing is a real strategy being used — they just blame the competitor for it, while doing the same thing themselves.
How does the company that speaks loudest about safety become the biggest safety controversy?
Because "safety" as a brand and "safety" as an operation are two very different things. The Anthropic Mythos breach (April 2026, AI Business Review) happened precisely because of the real gap between their public safety rhetoric and their actual investment in day-to-day operational security. When safety is your core brand, a breach isn't just a technical problem — it's an identity crisis that exposes the distance between narrative and reality.
Time for You to Be the One Who Knows First
The AI doom narrative is written by the companies selling AI. Now you know how to read the writers.
Share this article — most people in your network still believe the opposite, and they deserve to know.
Or, save it for next time a tech CEO warns you that AI is going to end civilization — this article will change how you read all of that forever.